

Web APP编程模型和IO策略
现代大型高性能网站诸如淘宝,京东,微博,FB,知乎等等,网站架构涉及很多知识。像业务分层,软件分割模块化,分布式部署,集群服务器,负载均衡等技术可以帮助架构师将一个大的复杂的问题切分成小的简单的问题。这篇文章着眼于解决这些切好的小问题上,单机上有哪些编程实践或者模型可以很好的做到高并发。本人web开发小白一枚,写文章是想梳理自己的思路,求得大牛斧正,希望各位多多批判。文章的内容大多来自网上的阅读加上些自己的理解,文末附上参考阅读的文章。
一个极简高并发模型
因为有数年的嵌入式领域的经验,先说一下我认为的比较高效的处理模型。
- 硬件环境:单机30core, 1G Hz。
- 软件环境:6Wind fastpath,每个core上都是run-to-complete的endless loop.没有操作系统。
- 功能:一个超级简单的reverse proxy,具有load balance的简单功能。
衡量并发性能,我们看一下一个IP包从网口缓冲区收上来处理到发出去大约需要多长时间呢?
收+处理+发大概是500+1000+500=2000 cycles,时间也就是2us。单机1s内可以支持30*(1s/2us)=15,000,000 request/s的并发。屌炸天的并发能力了吧!原因有两个:
- 没有操作系统overhead。
- 包处理简单,IP层的处理,直接c函数调用,总共1000 cycle。
当然这是从嵌入式得来的经验,web开发中不可能这样,没有Nginx,没有web框架,没有lib没有各种open source,甚至没有Linux。回到原始社会造出飞机大炮来,这不把web开发者逼疯了。软件也是一个社会化协作的过程,os,framework,lib,opensource给开发者带来极大方便的同时,也伴随着性能的开销。如何在性能和可扩展性、维护性等其他指标找到一个平衡点,如何选择合适的编程模型,合适的第三方模块达到最小的overhead,这是成长为高手的开发者都会不断思考的问题。
High Performance architecture,这篇文章总结了四个性能杀手:
- 数据复制
- 上下文切换
- 动态内存分配
- 锁竞争
上面的编程模型之所以高效,就是将CPU用到极致,尽量避免这4种情况发生。心中有这么一个极简的高效模型,后面学习其他模式的时候可以暗做对比看一下到底会有哪些额外的开销。
常用的server端Linux高并发编程模型
Nginx Vs Apache
大名鼎鼎的Nginx使用了多进程模型,主进程启动时初始化,bind,监听一组sockets,然后fork一堆child processes(workers),workers共享socket descriptor。workers竞争accept_mutex,获胜的worker通过IO multiplex(select/poll/epoll/kqueue/…)来处理成千上万的并发请求。为了获得高性能,Nginx还大量使用了异步,事件驱动,non-blocking IO等技术。”What resulted is a modular, event-driven, asynchronous, single-threaded, non-blocking architecture which became the foundation of nginx code.”
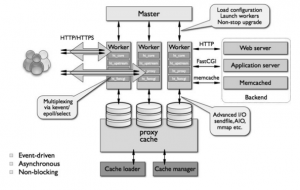
Nginx 架构
对比着看一下Apache的两种常用运行模式,详见 Apache Modules
- 1. Apache MPM prefork模式
主进程通过进程池维护一定数量(可配置)的worker进程,每个worker进程负责一个connection。worker进程之间通过竞争mpm-accept mutex实现并发和链接处理隔离。 由于进程内存开销和切换开销,该模式相对来说是比较低效的并发。
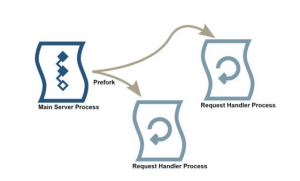
- 2. Apache MPM worker模式
由于进程开销较大,MPM worker模式做了改进,处理每个connection的实体改为thread。主进程启动可配数量的子进程,每个进程启动可配数量的server threads和listen thread。listen threads通过竞争mpm-accept mutex获取到新进的connection request通过queue传递给自己进程所在的server threads处理。由于调度的实体变成了开销较小的thread,worker模式相对prefork具有更好的并发性能。
小结两种webserver,可以发现Nginx使用了更高效的编程模型,worker进程一般跟CPU的core数量相当,每个worker驻留在一个core上,合理编程可以做到最小程度的进程切换,而且内存的使用也比较经济,基本上没有浪费在进程状态的存储上。而Apache的模式是每个connection对应一个进程/线程,进程/线程间的切换开销,大量进程/线程的内存开销,cache miss的概率增大,都限制了系统所能支持的并发数。
IO策略
由于IO的处理速度要远远低于CPU的速度,运行在CPU上的程序不得不考虑IO在准备暑假的过程中该干点什么,让出CPU给别人还是自己去干点别的有意义的事情,这就涉及到了采用什么样的IO策略。一般IO策略的选用跟进程线程编程模型要同时考虑,两者是有联系的。
同步阻塞IO
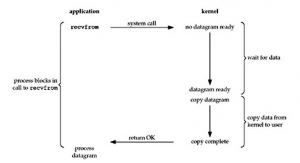
同步阻塞IO是比较常见的IO模型,网络编程中如果创建的socket的描述符属性设置为阻塞的,当socket对应的用户空间缓冲区内尚无可读数据时,该进程/线程在系统调用read/recv socket时,会将自己挂起阻塞等待socket ready。
同步非阻塞IO和非阻塞IO同步复用
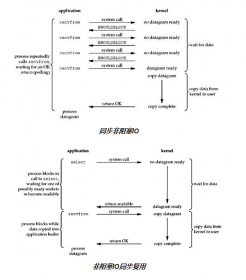
对比着同步阻塞IO,如果socket数据没有ready,系统调用read/recv会直接返回,进程可以继续执行不会挂起让出CPU。当然这样做对单个socket来说没有多大的意义,如果要支持大量socket的并发就很有用了,也就是IO复用。select/poll/epoll就是这样的应用,IO的read是非阻塞式调用,select是阻塞式的,同步发生在select上。程序通过select调用同时监控一组sockets,任何一个socket发生注册过的事件时,select由阻塞变为ready,函数调用返回后程序可以读取IO了。前面提到的Nginx(使用epoll)和apache(使用select)都有使用这一IO策略。select/epoll这种IO策略还有另外一个名字叫Reactor,具体他们之间的细节区别再另开一文。
异步非阻塞IO
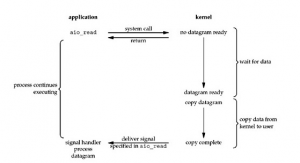
对比同步非阻塞IO,异步非阻塞IO也有个名字—Proactor。这种策略是真正的异步,使用注册callback/hook函数来实现异步。程序注册自己感兴趣的socket 事件时,同时将处理各种事件的handler也就是对应的函数也注册给内核,不会有任何阻塞式调用。事件发生后内核之间调用对应的handler完成处理。这里暂且理解为内核做了event的调度和handler调用,具体到底是异步IO库如何做的,如何跟内核通信的,后续继续研究。
原创作者招募ing
欢迎各位朋友加入马帮传道者写作团,秀出你的好身材,秀出你的好文章,让大家发现你的美,美在文章中,美在不断的自我挑战中!
马哥Linux运维微信公众号致力于发送好文章,也会不断发现身边的好文章,发现优秀的你,惠及更多的运维朋友们!
欢迎一起交流成长,一起愉快的玩耍!
原创投稿联系magedu-小助手QQ:152260971