

lvs集群学习笔记之原理
lvs集群学习笔记之原理
集群 负载均衡 lvs 原理
什么是集群
集群(Cluster):计算机集合为解决某个特定问题组合起来形成的单个系统 。
分为:
LB(Load Banlancing):负载均衡 HA(High Availability):高可用。提高服务可用性,避免出现单点故障 HP(High Performance):高性能 分布式存储与运算
什么是负载均衡
在现实情况中当我们遇到了单台服务器性能不足的时候,这时我们有两种提升方案:
Scale Up:向上扩展、垂直扩展、纵向扩展;用性能好的主机替代性能差的主机,性价比差; Scale Out: 向外扩展、水平扩展,即以新增服务器和现有服务器组成集群来应对性能不足的问题
在以上两种解决方案中我们一般选择向外扩展 因为:
向上扩展所付出的代价和得到性能的提升不成正比, 大多时候提升服务器一倍的性能需要花费三倍的价格 向外扩展也有很多问题, 例如:如何协调两台服务器提供一服务,用户在两台服务器进行轮调时如何保存其的session信息
负载均衡或者负载均衡集群的作用就是将:
**向外扩张的服务器群组组成一个负载均衡集群,前端通过负载均衡调度器来对用户请求通过调度算法合理分发到后端服务器中, 来达到负载均衡的目的.**
负载均衡解决方案
硬件解决方案: F5公司: BIG-IP Citrix公司: Netscaler A10公司: A10 Array Redware 软件解决方案: 四层: LVS 七层: HAproxy, Nginx, Varnish....
lvs简介
LVS(Linux Virtual Server)是目前阿里巴巴首席科学家章文嵩博士在大学期间的一款开源的负载均衡软件, 可实现四层的负载均衡。 首先解释下下文中出现的各种术语: Director: 负载均衡调度器, 负责在前端接受用户请求根据特定的算法转发到后端Real Server Real Server: 后端提供服务的服务器 VIP: Director接受用户请求的IP地址 DIP: Director和Real Server联系的IP地址 RIP: Real Server的IP地址 CIP: Client IP, 客户端的IP地址
lvs内核空间模型
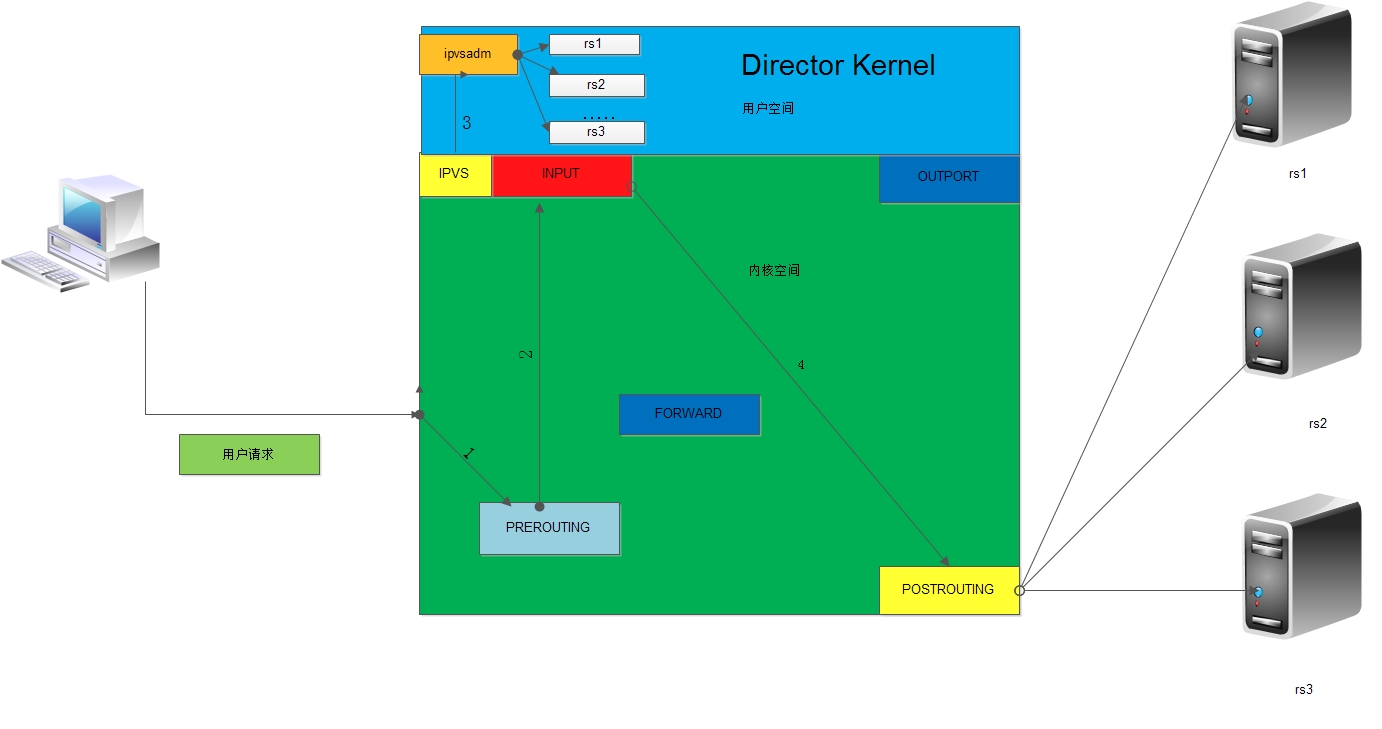
LVS其实由两个组件组成, 在用户空间的ipvsadm和内核空间的ipvs, ipvs工作在INPUT链上, 如果有请求报文被ipvs事先定义,就会将请求报文直接截取下根据其特定的模型修改请求报文, 再转发到POSTROUTING链上送出TCP/IP协议栈
其报文流经过程如下:
1.当客户端的请求到达负载均衡器的内核空间时,首先会到达PREROUTING链。 2.当内核发现请求数据包的目的地址是本机时,将数据包送往INPUT链。 3.LVS由用户空间的ipvsadm和内核空间的IPVS组成,ipvsadm用来定义规则,IPVS利用ipvsadm定义 的规则工作,IPVS工作在INPUT链上,当数据包到达INPUT链时,首先会被IPVS检查,如果数据包里 面的目的地址及端口没有在规则里面,那么这条数据包将被放行至用户空间。 4.如果数据包里面的目的地址及端口在规则里面,那么这条数据报文将被修改目的地址为事先定义 好的后端服务器,并送往POSTROUTING链。 5.最后经由POSTROUTING链发往后端服务器。
lvs特点
lvs具有以下特点: 1、ipvs工作于netfilter框架上。 2、 规则: 简单来说就是把ip加端口定义为ipvs集群服务,ipvs会为此请求定义一个或多个后端服务 目标地址未必会改,但是报文会被强行转发给后端的服务器。 3、ipvs组件: ipvsadm(用户空间,用来编写规则) + ipvs(内核空间) 4、ipvs工作在第四层: (1)四层交换、四层路由。 做第四层转发。(osi模型中的网络层) (2)只能基于ip和port转发,无法在应用层,session级别转发 (3) 不用到达应用层空间,就能转发 即工作在第四层不能进行7层负载均衡,但基于4层可以不要管上层协议进行负载均衡,只要支持 tcp或udp就行。 5、 lvs 性能很好,但是由于只第四层,不能到用户空间,因此不能进行更加精细的控制。 在精细控制方面,haproxy和Ngnix可以更好的实现。 6、lvs通常作为总入口,更精细化的切割可能使用,haproxy或者Nginx实现
lvs实现方式
lvs的实现方法为实现模型和负载均衡调度算法 实现模型为: 1、NAT 2、DR 3、TUN 4、FULLNAT 负载均衡调度算法分为两种:静态和动态 静态: RR WRR SH DH 动态: LC WLC SED NQ LBLC LBLCR 这些后文会一一介绍。
lvs实现方式之nat模型
如图实现过程如下:
1、客户端将请求发往前端的负载均衡器,请求报文源地址是CIP(客户端IP),后面统称为CIP),目标地址为VIP(负载均衡器前端地址,后面统称为VIP)。2、负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的目标地址改为了后端服务器的RIP地址并将报文根据算法发送出去。 3、报文送到Real Server后,由于报文的目标地址是自己,所以会响应该请求,并将响应报文返还给LVS。 4、然后lvs将此报文的源地址修改为本机并发送给客户端。注意:在NAT模式中,Real Server的网关必须指向LVS,否则报文无法送达客户端。 5、 NAT模型其实就是一个多路的DNAT,客户端对VIP进行请求,Director通过事先指定好的调度算法计算出应该转发到哪台RS上, 并修改请求报文的目标地址为RIP,通过DIP送往RS. 当RS响应客户端报文给CIP,经过Director时,Director又会修改源地址为VIP并将响应报文发给客户端. 这段过程对于用户来说是透明的.
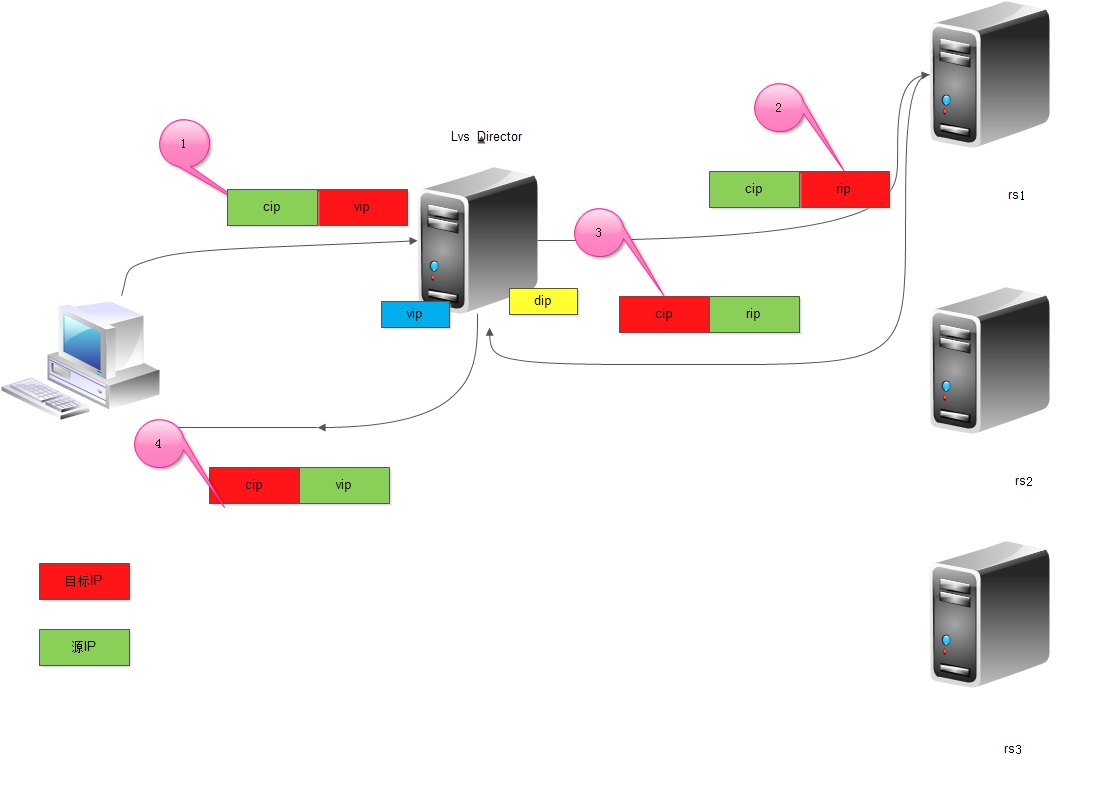
关于nat模型有几点需要注意: 1、RS和Director必须要在同一个IP网段中 2、RS的网关必须指向DIP 3、可以实现端口映射 4、请求报文和响应报文都会经过Director 5、RS可以是任意操作系统 6、DIP和RIP只能是内网IP
lvs实现方式之dr
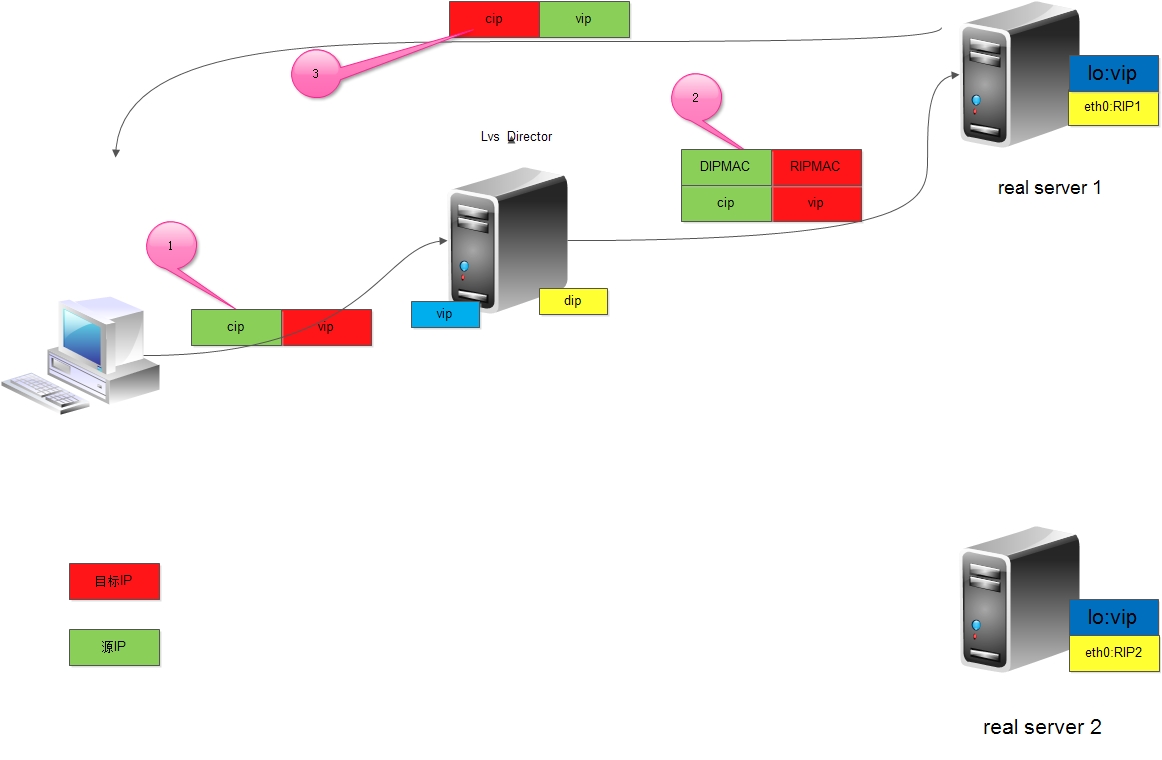
如图过程如下: 1、客户端将请求发往前端的负载均衡器,请求报文源地址是CIP,目标地址为VIP。 2、负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的源MAC地址改为自己DIP的MAC地址,目标MAC改为了RIP的MAC地址,并将此包发送给RS。 3、RS发现请求报文中的目的MAC是自己,就会将次报文接收下来,处理完请求报文后,将响应报文通过lo接口送给eth0网卡直接发送给客户端。注意:需要设置lo接口的VIP不能响应本地网络内的arp请求。 DR模型是一个较为复杂的模型. DR模型比较诡异, 因为VIP在Director和每一个RS上都存在, 客户端对VIP(Director)请求时,Director接收到请求会将请求报文的源MAC地址和目标MAC地址修改为本机DIP所在网卡的MAC地址和指定的RS的RIP所在网卡的MAC地址, RS接收到请求报文后直接对CIP发出响应报文, 而不需要通过Director
实现DR模型有一个最为关键的问题,大家都知道Linux主机配置一个IP地址会向本网络进行广播来通告其他主机或网络设备IP地址对应的MAC地址,那么VIP分别存在于Director和RS,IP不就冲突了么,我们该如何解决这个问题?
事实上LVS并不能帮助我们解决这个麻烦的问题:
我们有很多种方法可以解决上面的问题:
1、网络设备中设置VIP地址和DIrector的MAC地址进行绑定
2、Linux系统中有一个软件可以实现对ARP广播进行过滤, arptables
3、可以修改内核参数来实现, arp_ignore, arp_announce
实现DR模型需要注意的:
1、RS和Director可以不在同一IP网段中, 但是一定要在同一物理网络中
2、请求报文必须经过Director, 但是响应报文一定不能通过Director
3、RS的网关不能是Director
4、不能实现端口映射
5、RS可以是大部分操作系统
6、DIP和RIP可以是公网地址
lvs实现方式之tun
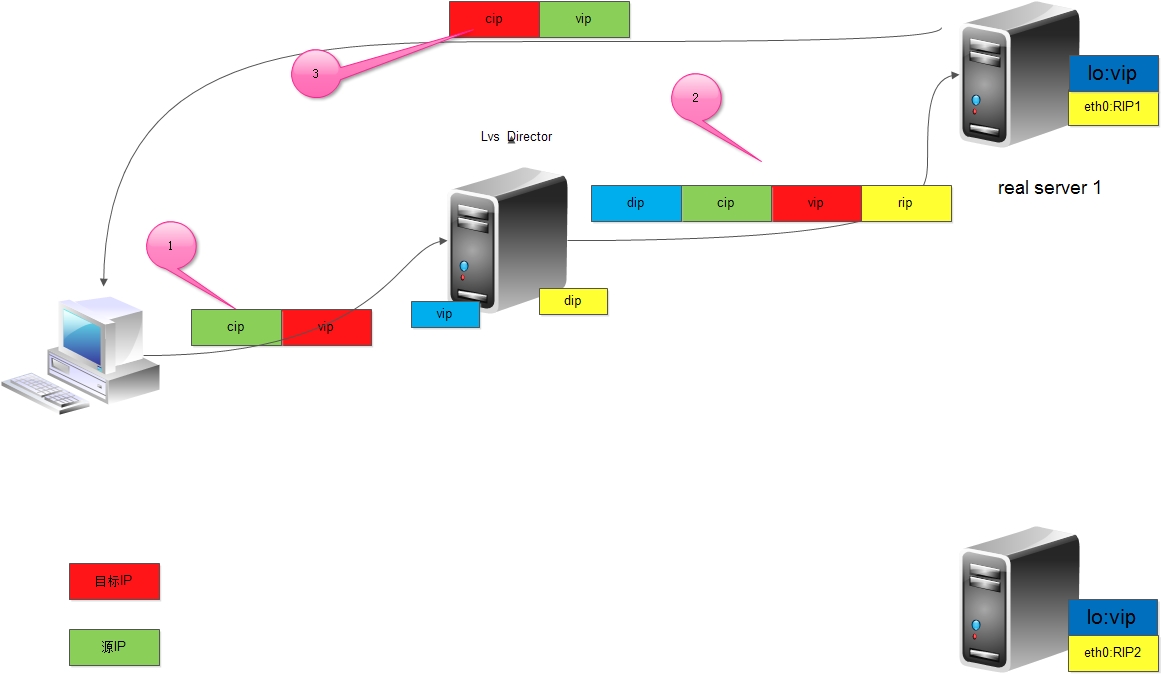
如图tun工作流程如下: 1、客户端将请求发往前端的负载均衡器,请求报文源地址是CIP,目标地址为VIP。 2、负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将在客户端请求报文的首部再封装一层IP报文,将源地址改为DIP,目标地址改为RIP,并将此包发送给RS。 3、RS收到请求报文后,会首先拆开第一层封装,然后发现里面还有一层IP首部的目标地址是自己lo接口上的VIP,所以会处理次请求报文,并将响应报文通过lo接口送给eth0网卡直接发送给客户端。注意:需要设置lo接口的VIP不能在共网上出现。 tun模型原理如下: TUN模型通过隧道的方式在公网中实现请求报文的转发,客户端请求VIP(Director),Director不修改 请求报文的源IP和目标IP,而是在IP首部前附加DIP和对应RIP的地址并转发到RIP上,RS收到请求报 文, 本地的接口上也有VIP, 遂直接响应报文给CIP。
需要注意的要点是: 1、RIP,DIP,VIP都是公网地址 2、RS的网关不能指向DIP 3、请求报文必须通过Director, 响应报文一定不能经过Director 4、不支持端口映射 5、RS的操作系统必须支持隧道功能
lvs实现方式之FULLNAT

FULLNAT实现原理: FULLNAT是近几年才出现的,客户端请求VIP(Director),Director修改请求报文的源地址(DIP)和目标地址(RIP)并转发给RS, FULLNAT模型一般是Director和RS处在复杂的内网环境中的实现。 实现FULLNAT模型需要注意的: 1、VIP是公网地址, DIP和RIP是内网地址, 但是无需在同一网络中 2、请求报文需要经过Director, 响应报文也要通过Director 3、RIP接收到的请求报文的源地址为DIP,目标地址为RIP 4、支持端口映射 5、RS可以是任意的操作系统
lvs之算法
lvs到底是根据什么来将请求负载均衡到real server上去的呢?
事实上lvs支持10中算法来决定如何将用户请求调度到real server上去。
调度算法分为两种:静态算法和动态算法。
静态调度算法: 根据算法本身进行调度, 不考虑RS的状态
动态调度算法: 根据算法和RS的实时负载进行调度
静态算法
①.RR:轮询调度(Round Robin) 调度器通过”轮叫”调度算法将外部请求按顺序轮流分配到集群中的真实服务器上,它均等地对待每一台服务器,而不管服务器上实际的连接数和系统负载。 ②.WRR:加权轮询(Weight RR) 调度器通过“加权轮叫”调度算法根据真实服务器的不同处理能力来调度访问请求。这样可以保证处理能力强的服务器处理更多的访问流量。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。 ③.DH:目标地址散列调度(Destination Hash ) 根据请求的目标IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。 ④.SH:源地址 hash(Source Hash) 源地址散列”调度算法根据请求的源IP地址,作为散列键(HashKey)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
动态算法
①.LC:最少链接(Least Connections) 调度器通过”最少连接”调度算法动态地将网络请求调度到已建立的链接数最少的服务器上。如果集群系统的真实服务器具有相近的系统性能,采用”最小连接”调度算法可以较好地均衡负载。 ②.WLC:加权最少连接(默认采用的就是这种)(Weighted Least Connections) 在集群系统中的服务器性能差异较大的情况下,调度器采用“加权最少链接”调度算法优化负载均衡性能,具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。 ③.SED:最短延迟调度(Shortest Expected Delay ) 在WLC基础上改进,Overhead = (ACTIVE+1)*256/加权,不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的,接受下次请求,+1的目的是为了考虑加权的时候,非活动连接过多缺陷:当权限过大的时候,会倒置空闲服务器一直处于无连接状态。 ④.NQ永不排队/最少队列调度(Never Queue Scheduling NQ) 无需队列。如果有台 realserver的连接数=0就直接分配过去,不需要再进行sed运算,保证不会有一个主机很空间。在SED基础上无论+几,第二次一定给下一个,保证不会有一个主机不会很空闲着,不考虑非活动连接,才用NQ,SED要考虑活动状态连接,对于DNS的UDP不需要考虑非活动连接,而httpd的处于保持状态的服务就需要考虑非活动连接给服务器的压力。 ⑤.LBLC:基于局部性的最少链接(locality-Based Least Connections) 基于局部性的最少链接”调度算法是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。 ⑥. LBLCR:带复制的基于局部性最少连接(Locality-Based Least Connections with Replication) 带复制的基于局部性最少链接”调度算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。该算法根据请求的目标IP地址找出该目标IP地址对应的服务器组,按”最小连接”原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按“最小连接”原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。