

sleep()到底睡多久,你知道吗?

丁铎
2014年毕业加入腾讯,对终端的性能测试有丰富的经验,《Android移动性能实战》作者之一,现在从事后台的性能测试。
***本文共2008个字,阅读需要5分钟,本文经授权转自腾讯蓝鲸(微信号:Tencent_lanjing)
1. 背景
最近负责一个很简单的需求:在服务器上起一个后台进程,每隔10秒钟上报一下CPU、内存等信息。就是这么简单的需求,发生了一个有趣的问题。
通过数据库查看上报的数据,发现Windows服务器在5月24号14:59到15:12之间,少上报了一个数据,少上报的数据会用null填充。但是看子机上的日志,这段时间均是按照预设的间隔成功上报,那问题出在哪儿呢?
开发一时也是一脸茫然,建议把测试时间调长,看是否能找到规律。好吧,那就把测试时间改到19个小时,这下还真的发现了一点规律。
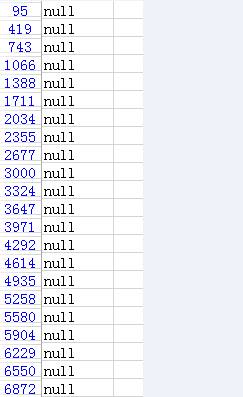

上图第一列是这段时间上报的数据点序列,即第95个点,第419个点,第二列是上报的信息,把所有的null过滤出来,看到相邻行的序号相差都在320~330之间,换算成时间,就是大概55分钟会少上报一个数据。
2. 原因排查
虽然找到了掉点的规律,但是从子机日志看都是上报成功的,是因为子机在这段时间就少采集了一个点吗?如果是这样的话,那么每次采样周期应该是超过10s的。
下面是信息采集上报的主循环代码,这里m_iInterval为5,也就是在每个采样周期内,这个循环会执行两次,然后上报这两次中最大的值。
int nmISensor::execute(){ m_iInterval = INTERVAL;while(m_bFlag){updateData();Sleep(m_iInterval*1000);}m_acq=1;return SUCCEED;}
2.1 猜测1:updateData()有耗时,导致整个循环周期的时间大于预期
从上面的代码可以看出,每个上报周期,代码的执行逻辑如下示意图,我们第一反应是updateData()的执行肯定也会耗时,那么会导致整个采样周期大于10s。一段时间后,就会少上报一个数据,幸福好像来的太突然。
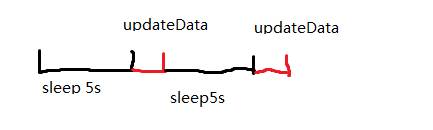
为了验证这个猜想,我们统计了一下updataData()的耗时,统计的结果看updateData()耗时都是0,也就是updateData()基本上是不耗时的,事实和我们预想的并不一样。
2.2 猜想2:Sleep()有误差
排除了updeData()的原因,现在只能把目光聚焦在Sleep函数上,难道是Windows的Sleep函数实际休眠的时间和预期有差异?为了验证这个猜想,我们又在日志中打出了Sleep实际执行的耗时和预期之间的差异。
这次好像看到了希望,从输出的日志看,Sleep最终休眠的时间会比预期多15ms,这样以来,每个上报周期就会多30ms,也就是在55分钟内可以上报330个点,现在只能上报329个点。
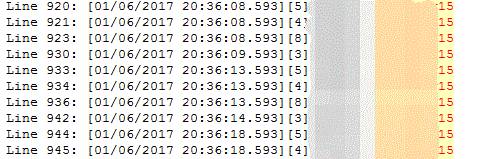
那么问题来了,为什么在Windows上Sleep()会比预期的多15ms呢?
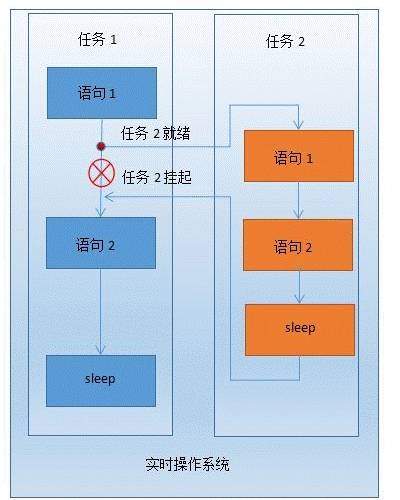
我们知道Windows操作系统基于时间片来进行任务调度的,Windows内核的时钟频率为64HZ,也就是每个时间片是15.625同时Windows也是非实时操作系统。对于非实时操作系统来说,低优先级的任务只有在子机的时间片结束或者主动挂起时,高优先级的任务才能被调度。下图直观地展示了两类操作系统的区别。
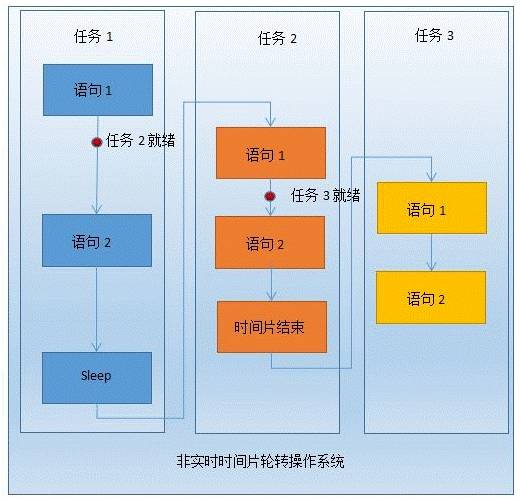
MSDN 上对Sleep()的说明:Sleep()需要依赖内核的时间片,如果休眠时间在1~2时间片之间,那么最终等待的时间会是1个或者2个时间片,也就是Sleep()会有0-15.625(1个时间片)的误差,那么到这里我们的问题也就弄清楚了。

3. 解决方案
3.1 官方方案
微软官方针对Sleep耗时不精确的问题,也给出相应的解决方案:
-
调用timeGetDevCaps获取时钟定时器能支持的最小粒度
-
在定时开始之前调用timeBeginPeriod,这样会把时钟定时器设置为最小的粒度
-
在定时结束之后调用 timeEndPeriod,恢复时钟定时器的粒度
同时,官方文档也指出timeBeginPeriod会对系统时钟、系统耗电和任务调度有影响,也就是timeBeginPeriod虽好,当不能滥用。
3.2 开发的方案
开发最后没有采用官方给的方案, 毕竟频繁调用timeBeginPeriod,带来的影响很难预估。而是采用了比较巧妙的方法:本次等待时长会减去上次多等的时间,即如果上次多等了15ms,那么下次只用等4895ms就可以了,这样可以保证每次循环周期是10s。
dwStart = GetTickCount();Sleep(dwInterval);dwDiff = GetTickCount() - dwStart - dwInterval;dwInterval = m_iInterval*1000;if (((long)dwDiff > 0) && (dwDiff < dwInterval)){dwInterval -= dwDiff;}
写到这里,问题已经解决,这时又有个疑惑涌上心头,Linux服务器上有同样的上报功能,为什么Linux子机没有这个问题呢?难道Linux对应的开发是大婶,已了然这一切?
4. Linux系统上sleep()是怎样的呢?
找到了Linux上对应的代码,原来这个开发哥并没有像Windows的开发哥那样自己去写一个定时的任务调度,而是用了一个开源的任务调度库APScheduler,才免遭遇难。看来这里的奥秘都在这个开源库中,接着就去看看APScheduler是怎样做任务调度的。 APScheduler主循环的代码如下,红框圈出了一行关键的代码,这行代码的意思是:本次任务执行完成之后,在下次任务开始前需要等待wait_sechonds的时间。
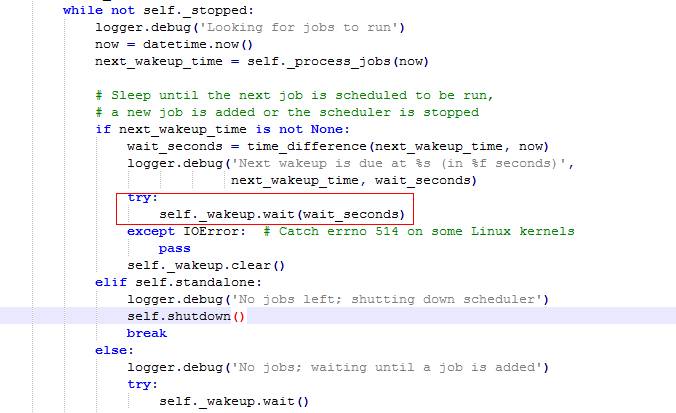
而self._wakeup是一个Event的对象,而Event正是Python系统库threading 中定义的。而Event常用来做多线程的同步。
def __init__(self, gconfig={}, **options): self._wakeup=Event()
官网对Event.wait()的解释:调用wait()之后,线程会一直阻塞,直到内部的flag设置为true,或者超时。在没有别的线程设置internal flag时,wait()就可以起到一个定时器的作用。
wait([timeout])Block until the internal flag is true. If the internal flag is true on entry, return immediately. Otherwise, block until another thread calls set() to set the flag to true, or until the optional timeout occurs.
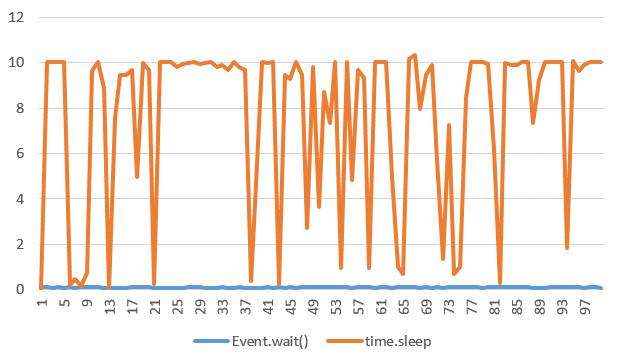
那么问题又来了,Event.wait()如果用作定时器,误差是多少呢?写个demp验证一下。
从测试数据看,Event.wait()取100次的平均偏差为0.1ms,而time.sleep()的平均偏差为7.65ms,看起来Event.wait()精度更高。
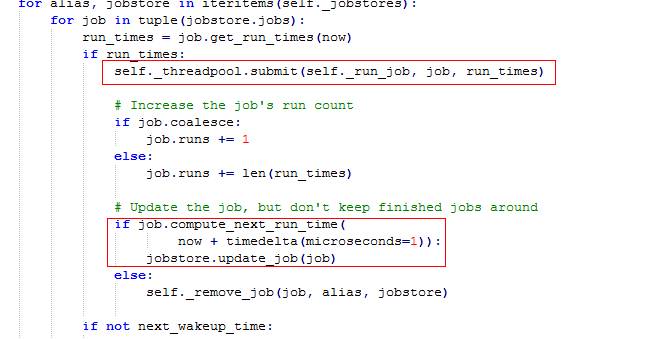
这里再回到我们第一个猜想,其实我们的猜想是合情合理的,如果updateData()的耗时较长,整个循环周期必定会超过预定的值,所以这里的实现并不严谨,而 APScheduler则是通过起一个新的线程去执行任务,并不会阻塞循环周期,可以看到APScheduler在这里处理的还是很合理的。
5. 结论
啰嗦了这么多,总结一下上面的内容:
-
sleep()在Windows和Linux系统上和预设值都会存在一个偏差,偏差最大为1个时间片的时间;
-
Event.wait()用来做定时器精度会更高,可以达到0.1ms;
-
APScheduler看起来是个不错的任务调度库。
“Linuxy云计算25期开班倒计时5天”
