今天给大家分享一篇来自于某大公司运维工程师的文章。在Linux运维的工作中,大数据运维总是要与hadoop打交道,那么在面对hadoop相关问题的时候,运维工程师应该怎么做?又该如何提高自己的效率呢?
本文是在工作过程中讲Zeppelin启用https过程和Hack内核以满足客户需求的记录。
原因是这客户很有意思,该客户中国分公司的人为了验证内网安全性,从国外找了一个渗透测试小组对Zeppelin和其他产品进行黑客测试,结果发现Zeppelin主要俩问题,一个是在内网没用https,一个是zeppelin里面可以执行shell命令和Python语句。其实这不算大问题,zeppelin本来就是干这个用的。但是渗透小组不了解zeppelin是做什么的,认为即使在内网里,执行shell命令能查看操作系统的一些文件是大问题,然后发生的事就不说了,不是我们的问题了。
不过既然他们要求整改,我们也只好配合,虽然大家都觉得内网域名加https属于脱了裤子放屁,然后不让zeppelin干他本来应该干的事就更过分了,但鉴于客户是甲方,也只好hack源码了。
于是某个周末用了4个小时完成所有工作。
先记录下zeppelin加https访问,我们有自己的域名证书,所以直接用即可。如果没有域名证书,需要自签发,那么可以看第二部分,双向认证步骤。
https第一部分,已有域名添加jks:


https第二部分,自签发证书双向认证添加jks
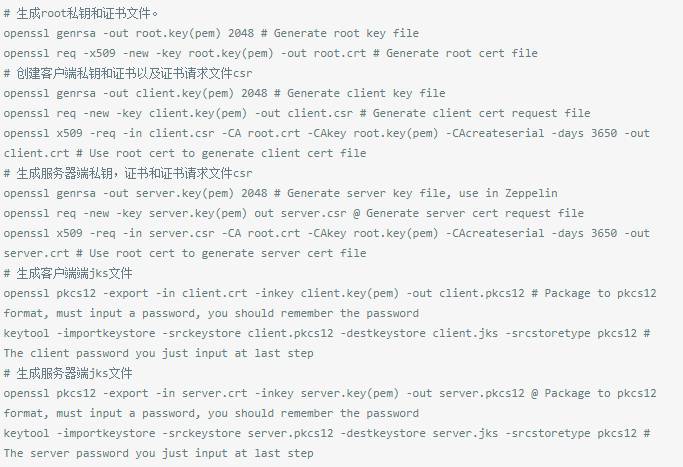
如果是不需要双向认证,只要单向自签发,不创建客户端的各种就可以了。
然后找个地把这些文件放过去,再修改zeppelin配置即可。

然后反代那里也加上443的ssl证书以及443转8443的upstream即可。
然后是hack zeppelin源码加入关键字限制,这个确实找了一小会zeppelin发送执行源码给interpreter的地方,zeppelin架构比较清晰,但是代码挺复杂的,用到了很多小花活儿。比如thrift,interpreter脚本里建立nc监听。然后各个解释器插件用socket跟interpreter脚本通信,前端angular,后端jetty,还用shiro做验证和授权。回头可以单开好几篇说说zeppelin安装,使用和详细配置,做这项目基本把zeppelin摸透了。
找到发送前端编写内容给interpreter的java代码,然后用很生硬的办法限制执行命令。具体那个.java文件的名字我就不说了,有悬念有惊喜。我不写java,只负责读源码找到代码位置,hack的java是同事写的。然后编译,替换jar包,完成。后面改了改配置,后续的渗透测试顺利通过。

因为客户有deadline限制,所以快速定位源码位置的过程还是挺有意思的,比较紧张刺激,在这个以小时计算deadline压力下,什么intelliJ, Eclipse都不好使啊,就grep和vi最好用,从找到到改完,比客户定的deadline提前了好几个小时。
作者:Slaytanic
来源:http://slaytanic.blog.51cto.com/2057708/1978521

