

我用Python又爬虫了拉钩招聘,给你们看看2019市场行情
本文转载自公号Python攻城狮,作者:Python攻城狮


数据采集
事情的起源是这样的,某个风和日丽的下午… 习惯性的打开知乎准备划下水,看到一个问题刚好邀请回答

于是就萌生了采集下某招聘网站Python岗位招聘的信息,看一下目前的薪水和岗位分布,说干就干。
先说下数据采集过程中遇到的问题,首先请求头是一定要伪装的,否则第一步就会给你弹出你的请求太频繁,请稍后再试,其次网站具有多重反爬策略,解决方案是每次先获取session然后更新我们的session进行抓取,最后拿到了想要的数据。
Chrome浏览器右键检查查看network,找到链接https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
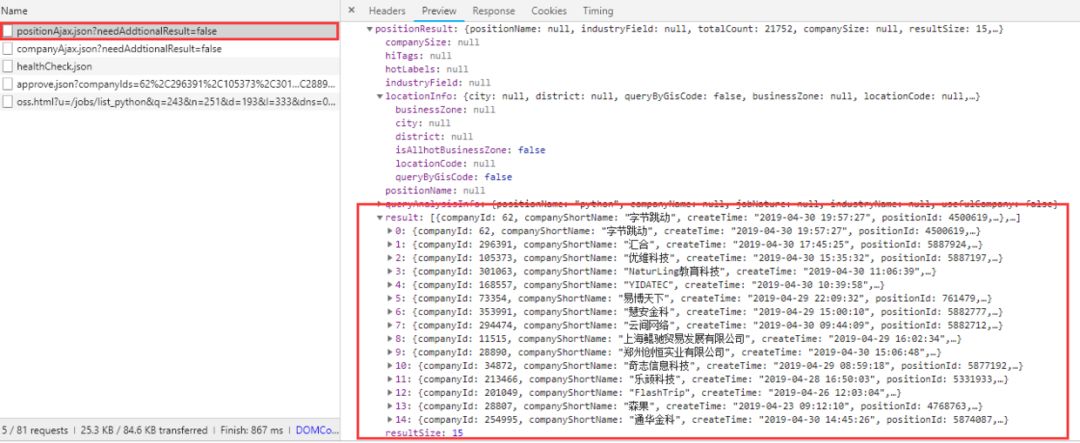
可以看到返回的数据正是页面的Python招聘详情,于是我直接打开发现直接提示{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"124.77.161.207","state":2402},机智的我察觉到事情并没有那么简单

真正的较量才刚刚开始,我们先来分析下请求的报文,
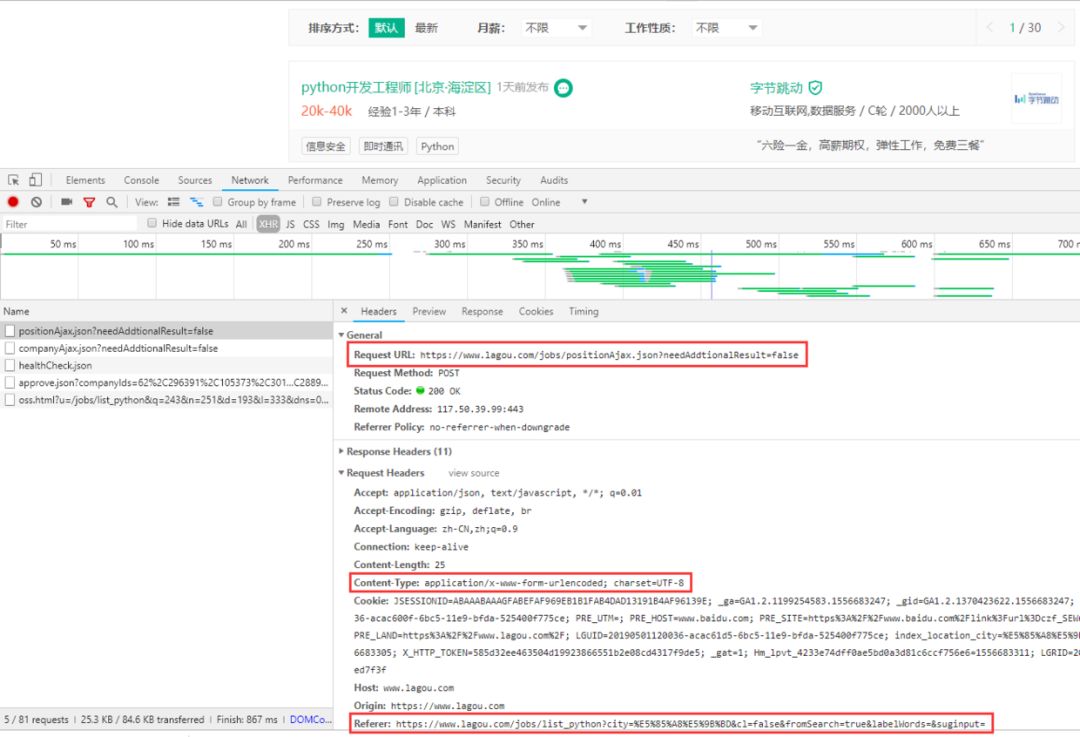
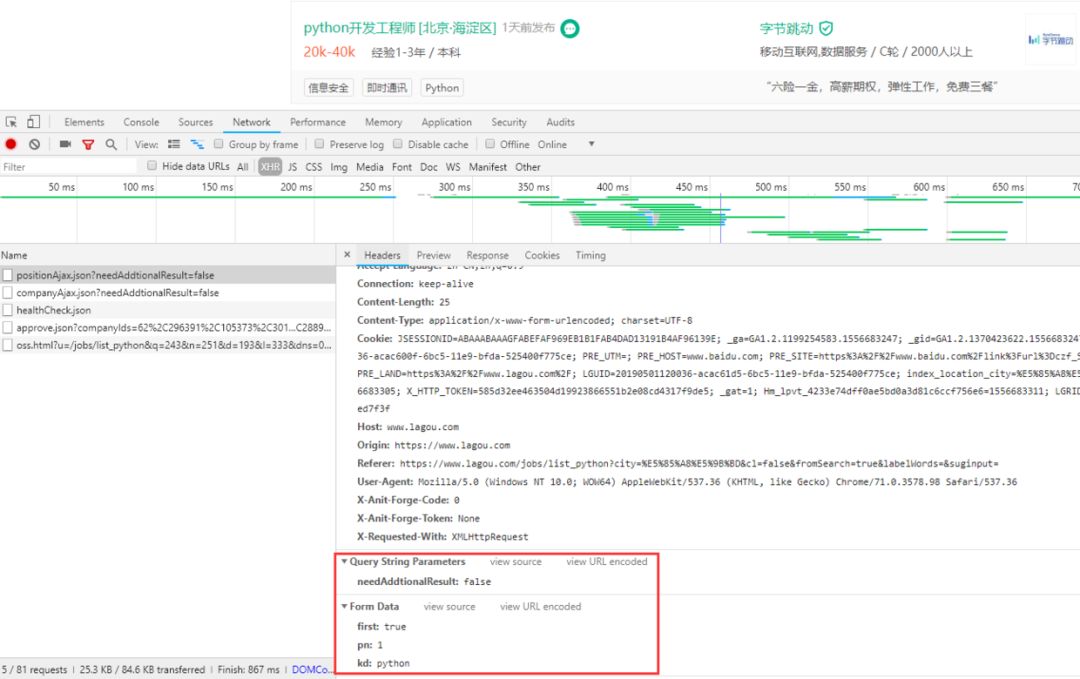
可以看到请求是以post的方式传递的,同时传递了参数
datas = { 'first': 'false', 'pn': x, 'kd': 'Python', }同时不难发现每次点击下一页都会同时发送一条get请求

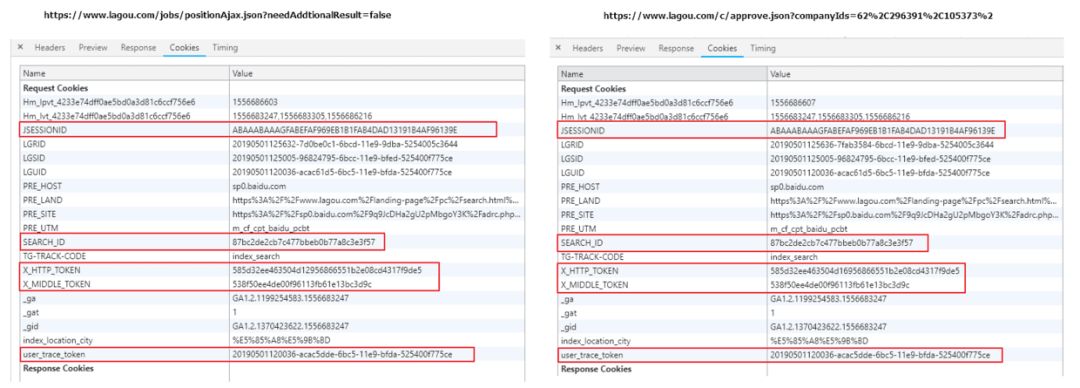
经过探索,发现这个get请求和我们post请求是一致的,那么问题就简单许多,整理一下思路
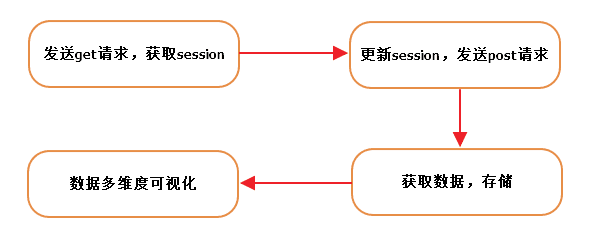
关键词:Python
搜索范围:全国
数据时效:2019.05.05
#!/usr/bin/env Python3.4# encoding: utf-8"""Created on 19-5-05@title: ''@author: Xusl"""import jsonimport requestsimport xlwtimport time# 获取存储职位信息的json对象,遍历获得公司名、福利待遇、工作地点、学历要求、工作类型、发布时间、职位名称、薪资、工作年限def get_json(url, datas): my_headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36", "Referer": "https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=", "Content-Type": "application/x-www-form-urlencoded;charset = UTF-8" } time.sleep(5) ses = requests.session() # 获取session ses.headers.update(my_headers) # 更新 ses.get("https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=") content = ses.post(url=url, data=datas) result = content.json() info = result['content']['positionResult']['result'] info_list = [] for job in info: information = [] information.append(job['positionId']) # 岗位对应ID information.append(job['city']) # 岗位对应城市 information.append(job['companyFullName']) # 公司全名 information.append(job['companyLabelList']) # 福利待遇 information.append(job['district']) # 工作地点 information.append(job['education']) # 学历要求 information.append(job['firstType']) # 工作类型 information.append(job['formatCreateTime']) # 发布时间 information.append(job['positionName']) # 职位名称 information.append(job['salary']) # 薪资 information.append(job['workYear']) # 工作年限 info_list.append(information) # 将列表对象进行json格式的编码转换,其中indent参数设置缩进值为2 # print(json.dumps(info_list, ensure_ascii=False, indent=2)) # print(info_list) return info_listdef main(): page = int(input('请输入你要抓取的页码总数:')) # kd = input('请输入你要抓取的职位关键字:') # city = input('请输入你要抓取的城市:') info_result = [] title = ['岗位id', '城市', '公司全名', '福利待遇', '工作地点', '学历要求', '工作类型', '发布时间', '职位名称', '薪资', '工作年限'] info_result.append(title) for x in range(1, page+1): url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' datas = { 'first': 'false', 'pn': x, 'kd': 'Python', } try: info = get_json(url, datas) info_result = info_result + info print("第%s页正常采集" % x) except Exception as msg: print("第%s页出现问题" % x) # 创建workbook,即excel workbook = xlwt.Workbook(encoding='utf-8') # 创建表,第二参数用于确认同一个cell单元是否可以重设值 worksheet = workbook.add_sheet('lagouzp', cell_overwrite_ok=True) for i, row in enumerate(info_result): # print(row) for j, col in enumerate(row): # print(col) worksheet.write(i, j, col) workbook.save('lagouzp.xls')if __name__ == '__main__': main()
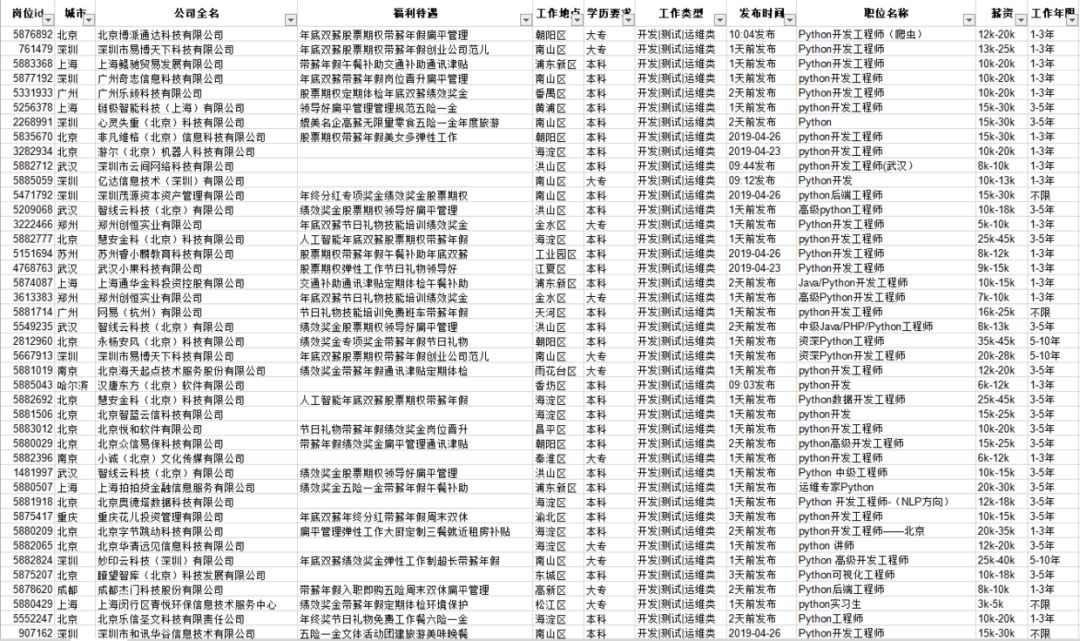
当然存储于excel当然是不够的,之前一直用matplotlib做数据可视化,这次换个新东西pyecharts。
了解pyecharts
pyecharts是一款将Python与echarts结合的强大的数据可视化工具,包含多种图表
- Bar(柱状图/条形图)
- Bar3D(3D 柱状图)
- Boxplot(箱形图)
- EffectScatter(带有涟漪特效动画的散点图)
- Funnel(漏斗图)
- Gauge(仪表盘)
- Geo(地理坐标系)
- Graph(关系图)
- HeatMap(热力图)
- Kline(K线图)
- Line(折线/面积图)
- Line3D(3D 折线图)
- Liquid(水球图)
- Map(地图)
- Parallel(平行坐标系)
- Pie(饼图)
- Polar(极坐标系)
- Radar(雷达图)
- Sankey(桑基图)
- Scatter(散点图)
- Scatter3D(3D 散点图)
- ThemeRiver(主题河流图)
- WordCloud(词云图)
用户自定义
- Grid 类:并行显示多张图
- Overlap 类:结合不同类型图表叠加画在同张图上
- Page 类:同一网页按顺序展示多图
- Timeline 类:提供时间线轮播多张图
另外需要注意的是从版本0.3.2 开始,为了缩减项目本身的体积以及维持 pyecharts 项目的轻量化运行,pyecharts 将不再自带地图 js 文件。如用户需要用到地图图表(Geo、Map),可自行安装对应的地图文件包。
- 全球国家地图: echarts-countries-pypkg (1.9MB): 世界地图和 213 个国家,包括中国地图
- 中国省级地图: echarts-china-provinces-pypkg (730KB):23 个省,5 个自治区
- 中国市级地图: echarts-china-cities-pypkg (3.8MB):370 个中国城市
也可以使用命令进行安装
pip install echarts-countries-pypkgpip install echarts-china-provinces-pypkgpip install echarts-china-cities-pypkg数据可视化(代码+展示)
- 各城市招聘数量
from pyecharts import Barcity_nms_top10 = ['北京', '上海', '深圳', '成都', '杭州', '广州', '武汉', '南京', '苏州', '郑州', '天津', '西安', '东莞', '珠海', '合肥', '厦门', '宁波', '南宁', '重庆', '佛山', '大连', '哈尔滨', '长沙', '福州', '中山']city_nums_top10 = [149, 95, 77, 22, 17, 17, 16, 13, 7, 5, 4, 4, 3, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1]bar = Bar("Python岗位", "各城市数量")bar.add("数量", city_nms, city_nums, is_more_utils=True)# bar.print_echarts_options() # 该行只为了打印配置项,方便调试时使用bar.render('Python岗位各城市数量.html') # 生成本地 HTML 文件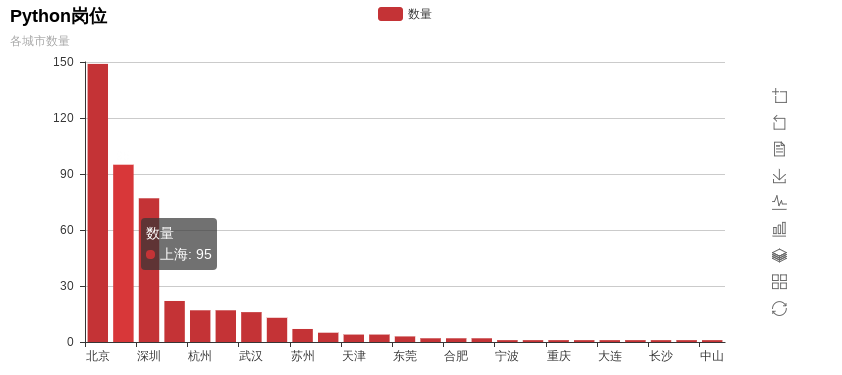
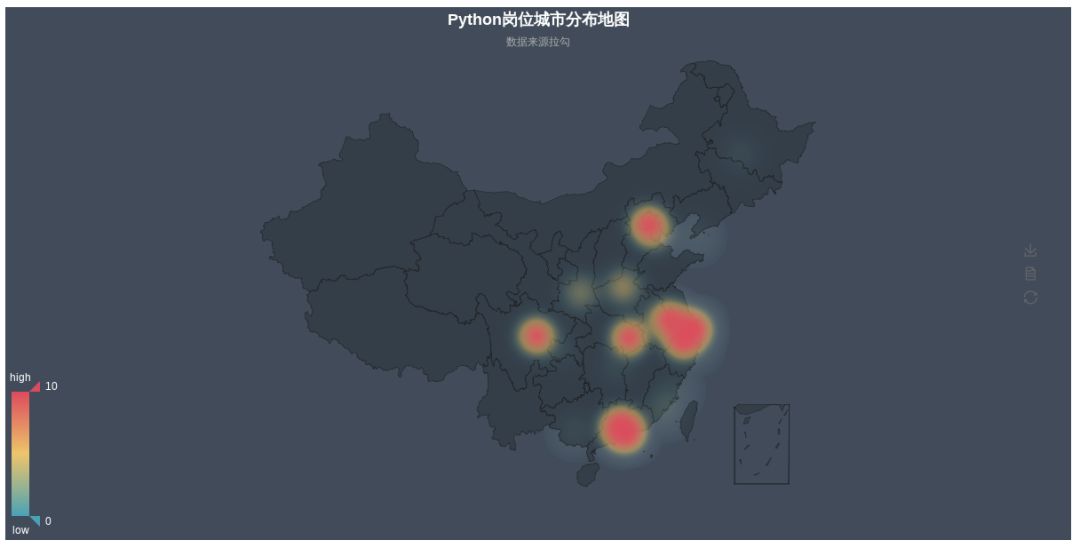
- 地图分布展示(这个场景意义不大,不过多分析)
from pyecharts import Geocity_datas = [('北京', 149), ('上海', 95), ('深圳', 77), ('成都', 22), ('杭州', 17), ('广州', 17), ('武汉', 16), ('南京', 13), ('苏州', 7), ('郑州', 5), ('天津', 4), ('西安', 4), ('东莞', 3), ('珠海', 2), ('合肥', 2), ('厦门', 2), ('宁波', 1), ('南宁', 1), ('重庆', 1), ('佛山', 1), ('大连', 1), ('哈尔滨', 1), ('长沙', 1), ('福州', 1), ('中山', 1)]geo = Geo("Python岗位城市分布地图", "数据来源拉勾", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')attr, value = geo.cast(city_datas)geo.add("", attr, value, visual_range=[0, 200], visual_text_color="#fff", symbol_size=15, is_visualmap=True)geo.render("Python岗位城市分布地图_scatter.html")geo = Geo("Python岗位城市分布地图", "数据来源拉勾", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59') attr, value = geo.cast(city_datas) geo.add("", attr, value, type="heatmap", visual_range=[0, 10], visual_text_color="#fff", symbol_size=15, is_visualmap=True) geo.render("Python岗位城市分布地图_heatmap.html")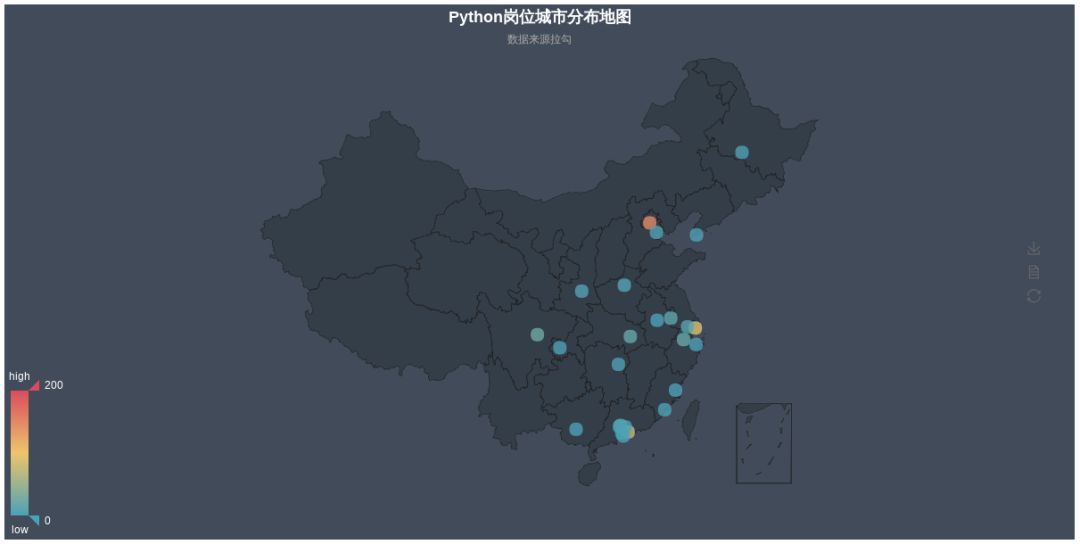
- 各个城市招聘情况
from pyecharts import Piecity_nms_top10 = ['北京', '上海', '深圳', '成都', '广州', '杭州', '武汉', '南京', '苏州', '郑州']city_nums_top10 = [149, 95, 77, 22, 17, 17, 16, 13, 7, 5]pie = Pie()pie.add("", city_nms_top10, city_nums_top10, is_label_show=True)# pie.show_config()pie.render('Python岗位各城市分布饼图.html')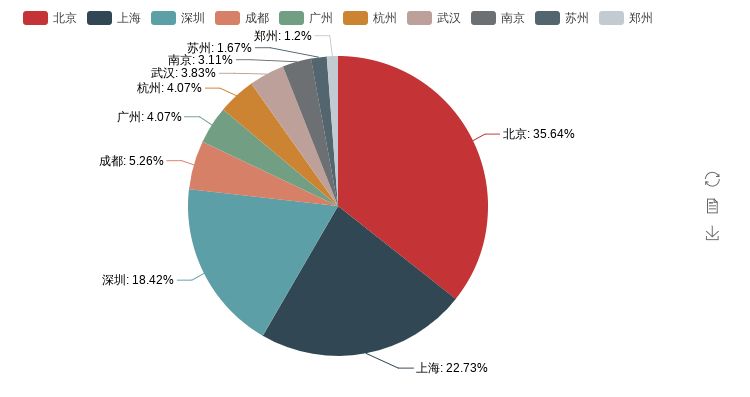
北上深的岗位明显碾压其它城市,这也反映出为什么越来越多的it从业人员毕业以后相继奔赴一线城市,除了一线城市的薪资高于二三线这个因素外,还有一个最重要的原因供需关系,因为一线岗位多,可选择性也就比较高,反观二三线的局面,很有可能你跳个几次槽,发现同行业能呆的公司都待过了…
- 薪资范围
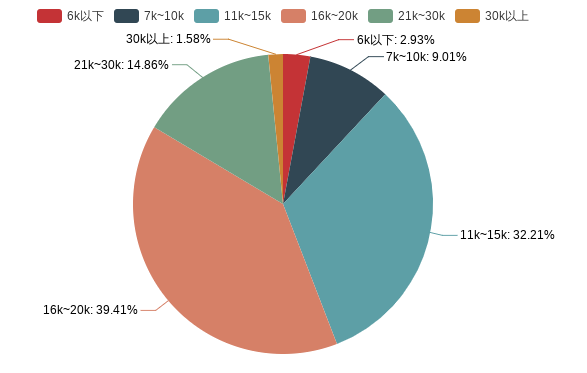
由此可见,Python的岗位薪资多数在10k~20k,想从事Python行业的可以把工作年限和薪资结合起来参考一下。
- 学历要求 + 工作年限
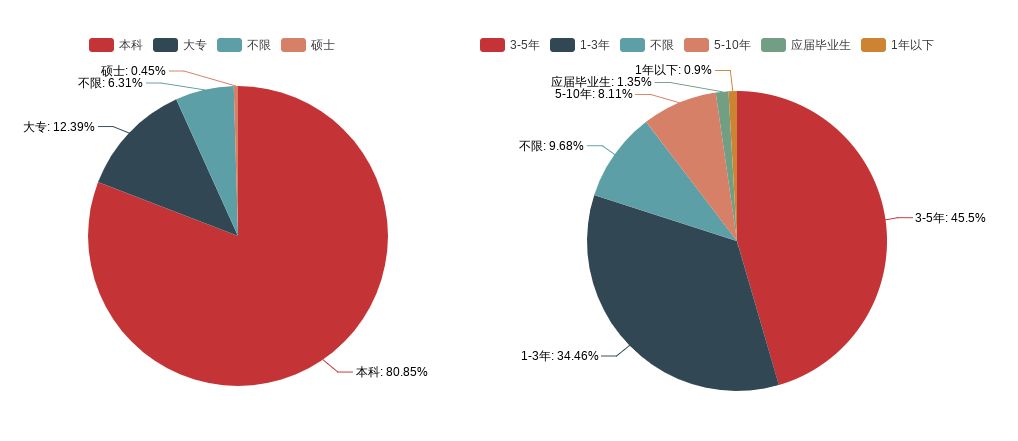
从工作年限来看,1-3年或者3-5年工作经验的招聘比较多,而应届生和一年以下的寥寥无几,对实习生实在不太友好,学历也普遍要求本科,多数公司都很重视入职人员学历这点毋容置疑,虽然学历不代表一切,但是对于一个企业来说,想要短时间内判断一个人的能力,最快速有效的方法无疑是从学历入手。学历第一关,面试第二关。
但是,这不代表学历不高的人就没有好的出路,现在的大学生越来越多,找工作也越来越难,竞争越来越激烈,即使具备高学历,也不能保证你一定可以找到满意的工作,天道酬勤,特别是it这个行业,知识的迭代,比其他行业来的更频密。不断学习,拓展自己学习的广度和深度,才是最正确的决定。
就业寒冬来临,我们需要的是理性客观的看待,而不是盲目地悲观或乐观。从以上数据分析,如果爱好Python,仍旧可以入坑,不过要注意一个标签有工作经验,就算没有工作经验,自己在学习Python的过程中一定要尝试独立去做一个完整的项目,爬虫也好,数据分析也好,亦或者是开发,都要尝试独立去做一套系统,在这个过程中培养自己思考和解决问题的能力。持续不断的学习,才是对自己未来最好的投资,也是度过寒冬最正确的姿势。
声明:文章来源于网络,侵删!