

一个Python小白如何快速完成爬虫?
今天马哥教育要跟大家分享的文章是一个Python小白如何快速完成爬虫?很人或多或少都听说过Python爬虫,但不知道如何通过Python爬虫来爬取自己想要的内容,Python入门新手和正在Python学习的小伙伴快来看一看吧,希望能够对大家有所帮助 !
环境搭建
既然用Python,那么自然少不了语言环境。于是乎到官网下载了3.5版本的。安装完之后,随机选择了一个编辑器叫PyCharm,话说Python编辑器还真挺多的。
建好项目,打开编辑器,直接开工。搜一个HTML解析工具,人家都做的那种,这事不要客气,直接拿来用-BeautifulSoup 。安装也很简单的。
发送请求
当然我也是不清楚Python是怎么进行网络请求的,其中还有什么2.0和3.0的不同,通过各种百度,最终还是写出了最简单的一段请求代码。
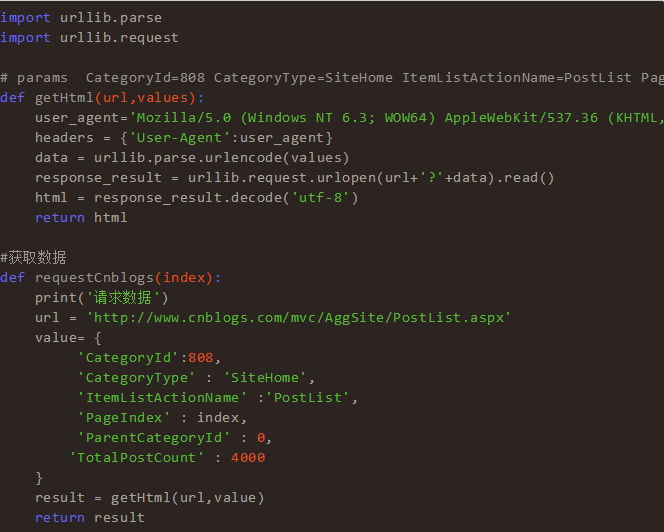
数据解析
上文已经提到了,用到的是BeautifulSoup,好处就是不用自己写正则,只要根据他的语法来写就好了,在多次的测试之后终于完成了数据的解析。先上一段HTML。然后在对应下面的代码,也许看起来更轻松一些。
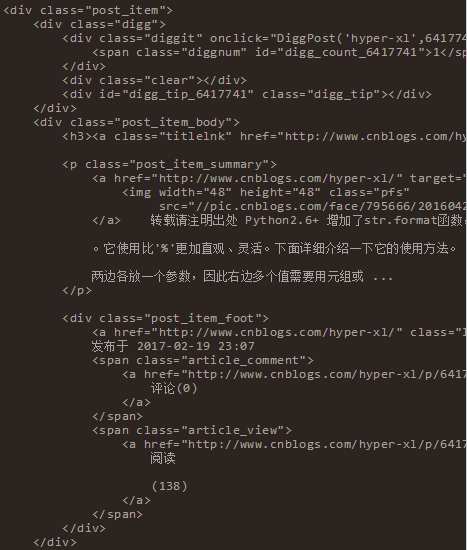
通过上文的HTML代码可以看到几点。首先每一条数据都在 div(class=”post_item”)下。然后 div(“post_item_body”)下有用户信息,标题,链接,简介等信息。逐一根据样式解析即可。代码如下:
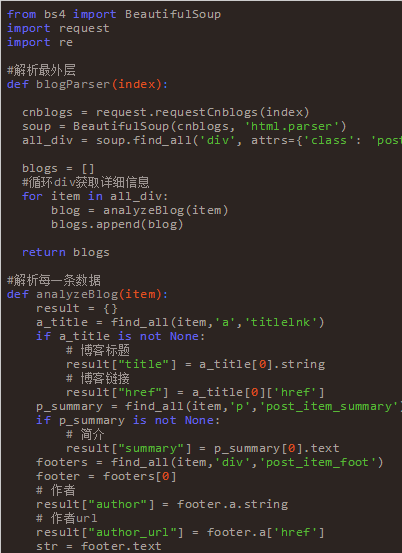
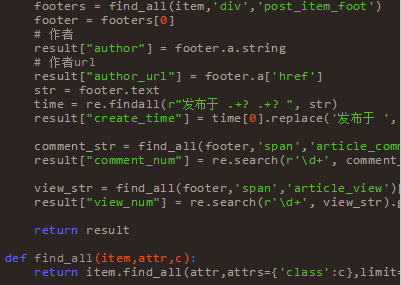
上边一堆代码下来,着实会花费不少时间,边写边调试,再百度,不过还好最终还是出来了。等数据都整理好之后,然后我把它保存到了txt文件里面,以供其他语言来处理。
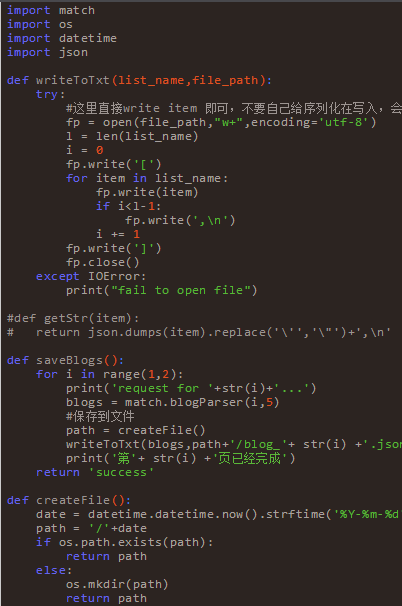
上边呢,我取了一百页的数据,也就是大概2000条做测试。
成果验收
废了好大劲终于写完那些代码之后呢,就欣赏自己的成果了,初学者代码通常写的很渣,不过当你真正完成了,你就会有一种莫名的自豪感。
以上就是马哥教育今天为大家分享的关于一个Python小白如何快速完成爬虫的文章,希望本篇文章能够对正在Python学习 和从事Python相关工作的小伙伴们有所帮助,想要了解更多相关知识记得关注马哥教育官网,每天都会有大量优质内容与大家分享!
声明:文章来源于网络,侵删!