

Python是如何查询天气的(4)
今天马哥教育要跟大家分享的文章是Python是如何查询天气的(4)?在上一讲我们已经可以查询天气了,但是是不是有人对城市代码的查询还感到不满意呢?今天我们就这里的内容再跟大家深入讲解一下,Python入门新手和正在Python学习的小伙伴快来看一看吧,希望能够对大家有所帮助 !
了解一下城市代码的抓取过程,也会让你对网页抓取有更深的理解哦。
天气网的城市代码信息结构比较复杂,所有代码按层级放在了很多xml为后缀的文件中。而这些所谓的“xml”文件又不符合xml的格式规范,导致在浏览器中无法显示,给我们的抓取又多加了一点难度。
首先,抓取省份的列表:
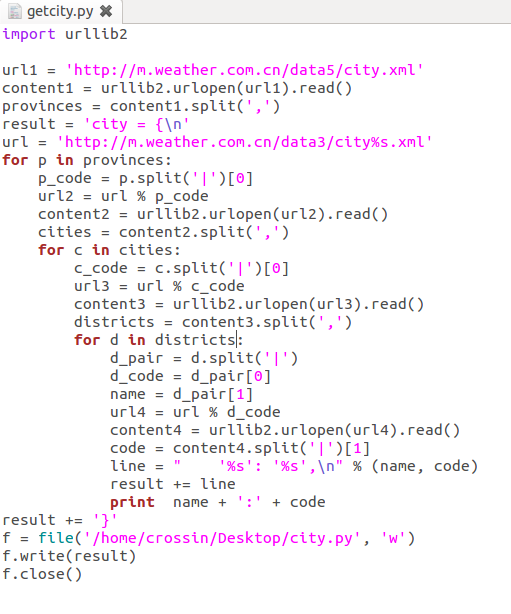
url1 = 'http://m.weather.com.cn/data5/city.xml'
content1 = urllib2.urlopen(url1).read()
provinces = content1.split(',')
输出content1可以查看全部省份代码:
01|北京,02|上海,03|天津,...
对于每个省,抓取城市列表:
url = 'http://m.weather.com.cn/data3/city%s.xml'
for p in provinces:
p_code = p.split('|')[0]
url2 = url % p_code
content2 = urllib2.urlopen(url2).read()
cities = content2.split(',')
输出content2可以查看此省份下所有城市代码:
1901|南京,1902|无锡,1903|镇江,...
再对于每个城市,抓取地区列表:
for c in cities[:3]:
c_code = c.split('|')[0]
url3 = url % c_code
content3 = urllib2.urlopen(url3).read()
districts = content3.split(',')
content3是此城市下所有地区代码:
190101|南京,190102|溧水,190103|高淳,...
最后,对于每个地区,我们把它的名字记录下来,然后再发送一次请求,得到它的最终代码:
for d in districts:
d_pair = d.split('|')
d_code = d_pair[0]
ame = d_pair[1]
url4 = url % d_code
content4 = urllib2.urlopen(url4).read()
code = content4.split('|')[1]
name和code就是我们最终要得到的城市代码信息。它们格式化到字符串中,最终保存在文件里:
line = " '%s': '%s',n" % (name, code) result += line
同时你也可以输出它们,以便在抓取的过程中查看进度:
print name + ':' + code
如果你只是想抓几个测试一下,并不用全部抓下来,在provices后面加上[:3],抓3个省的试试看就好了。
恭喜你在Python的道路上又坚持了一天,相信到今天为止,你可以毫无压力地跟别人说查询天气太简单了,一串代码的事!那你了解完了如何用Python去查询天气,那你可以查询下别的吗?比如火车票呢?思考一下,并试着动手实践一下吧!
以上就是马哥教育今天为大家分享的关于Python是如何查询天气的(4)的文章,希望本篇文章能够对正在 Python学习 和从事Python相关工作的小伙伴们有所帮助,想要了解更多相关知识记得关注马哥教育官网。最后祝愿小伙伴们工作顺利!
声明:文章来源于网络,侵删!