

Python中如何统计文本词汇出现的次数?
问题描述:
有时在遇到一个文本需要统计文本内词汇的次数的时候,可以用一个简单的python程序来实现。
解决方案:
首先需要的是一个文本文件(.txt)格式(文本内词汇以空格分隔),因为需要的是一个程序,所以要考虑如何将文件打开而不是采用复制粘贴的方式。这时就要用到open()的方式来打开文档,然后通过read()读取其中内容,再将词汇作为key,出现次数作为values存入字典。
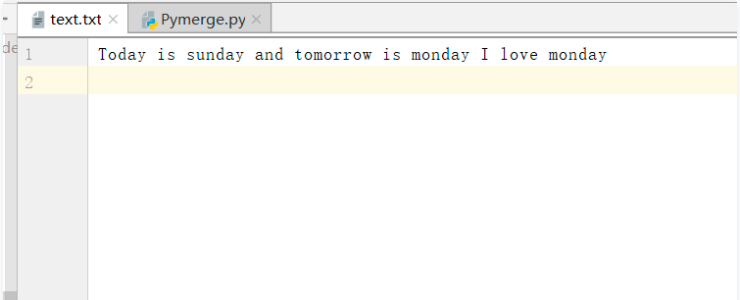
图 1 txt文件内容
再通过open和read函数来读取文件:
open_file=open("text.txt")
file_txt=open_file.read()
然后再创建一个空字典,将所有出现的每个词汇作为key保存到字典中,对文本从开始到结束,循环处理每个词汇,并将词汇设置为一个字典的key,将其value设置为1,如果已经存在该词汇的key,说明该词汇已经使用过,就将value累积加1。
代码示例:
def wordcount(readtxt):
readlist = readtxt.split()
dict1={}
for every_world in readlist:
if every_world in dict1:
dict1[every_world] += 1
else:
dict1[every_world] = 1
return dict1
print(wordcount(file_txt))
这里加了def函数把该程序封装成一个函数。
最后输出得到词汇出现的字典:
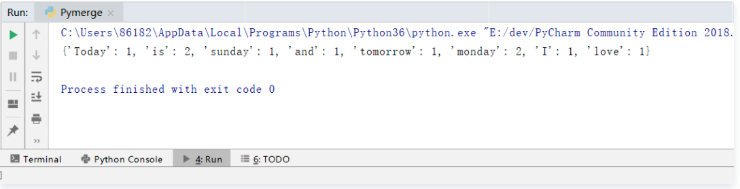
图 2 形成字典
版权声明:转载文章来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。