

2021年10个不错的Python库
这是第六届年度 Python 库排行榜。这个排行榜的依据是什么?规则很简单。我们寻找的库需要满足下列条件:
-
它们是在 2020 年推出或普及的。 -
它们从发布后就一直有良好的维护。 -
它们非常炫酷,很值得一看。
免责声明:今年,我们的选择受到机器学习 / 数据科学库的极大影响,虽然有些库对非数据科学家来说确实很有用。另外,尽管我们有 10 个主要的精选(以及一个奖励),但我们还是决定增加一个新的“荣誉提名”部分,以便公平对待我们发现但又不能遗漏的其他库。
1.Typer

你不必总是要编写 CLI 应用程序,但是在编写 CLI 时,最好是无障碍的体验。继 FastAPI 巨大成功之后,Sebastián Ramírez 用同样的原则为我们带来了 Typer:一个新的库,通过利用 Python 3.6+ 的类型提示功能,可以编写命令行界面。
这个设计确实使 Typer 脱颖而出。除确保你的代码被正确地记录下来外,你还可以通过最少的努力来获得一个带有验证的 CLI 接口。使用类型提示,你可以在 Python 编辑器中获得自动完成功能(比如 VSCode),从而提高工作效率。
为增强 Typer 功能,它的内部是基于 Click 开发的,Click 是非常著名的,并且已经通过了实战检验。这意味着,它可以利用其所有的优点、社区和插件,同时用较少的样板代码从简单的开始,并在需要时添加更多的复杂性。
一如既往,它的文档真的很出色,可以作为其他项目的典范。这绝对是不容错过的作品。
GitHub 项目地址:https://github.com/tiangolo/typer
2. Rich
接着 CLI 的话题,谁说终端应用程序必须是单调的白色,如果你是一个真正的 hacker,就必须是绿色的?那黑色呢?
你想为你的终端输出加上颜色和样式吗?在一瞬间打开复杂的表格?轻松地展示华丽的进度条?Markdown?Emojis?Rich 都能满足你的要求。请看下面的截图,来了解一下它的功能。
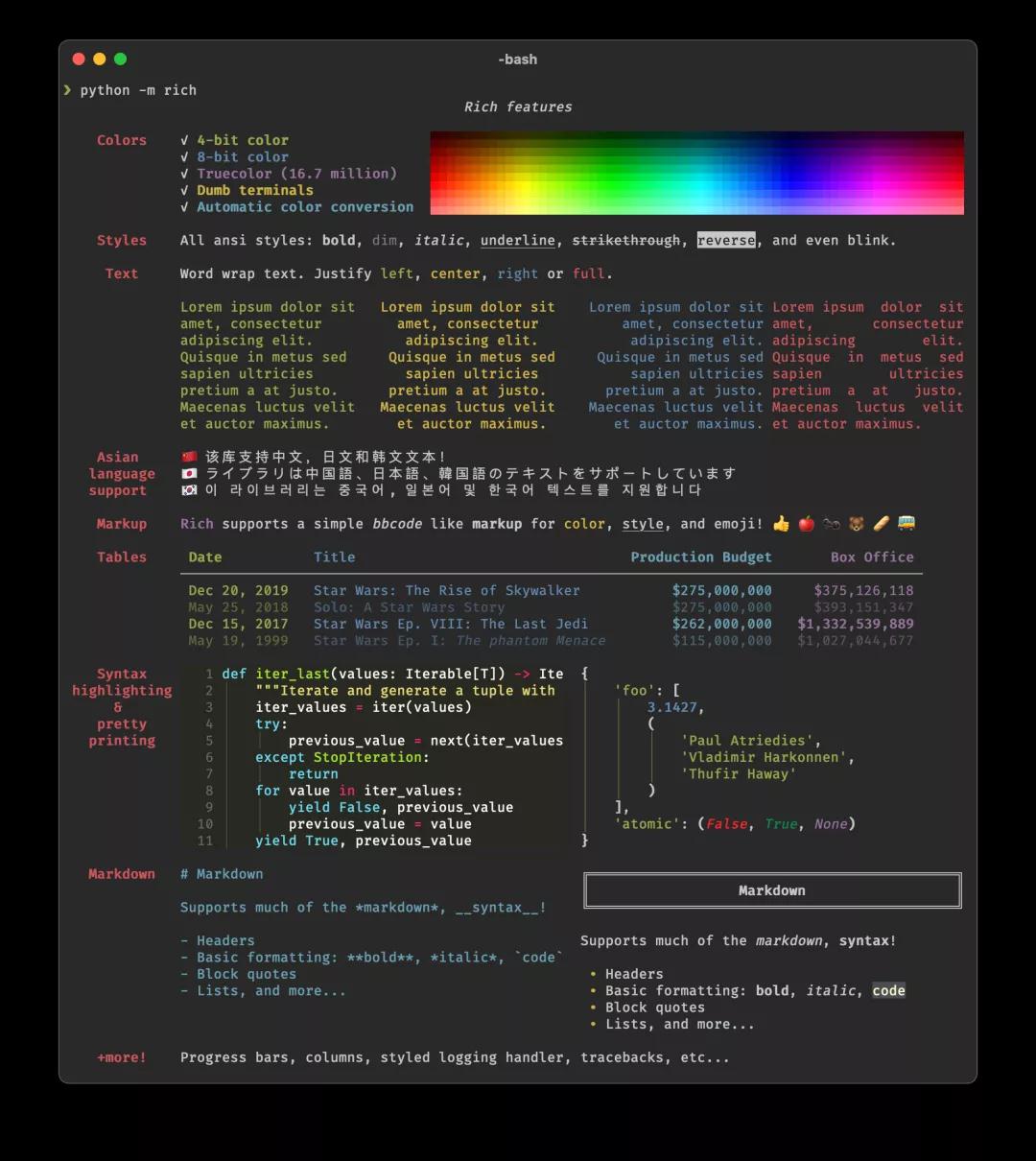
毫无疑问,这个库将终端应用的使用体验提高到了一个全新的水平。
GitHub 项目地址:https://github.com/willmcgugan/rich
3. Dear PyGui
就像我们看到的那样,终端应用可以做到很华丽,但有时候这还不够,你需要一个真正的 GUI。为此,Dear PyGui 应运而生,它是流行的 Dear ImGui C++ 项目的 Python 移植。
Dear PyGui 使用了一种被称为即时模式的范例,它在电子游戏中很流行。这基本上意味着动态 GUI 是逐帧独立绘制的,无需持久化任何数据。这样,这个工具与其他 Python GUI 框架就有了本质上的区别。它性能优异,并用计算机的 GPU 来促进高动态界面的构建,这在工程、模拟、游戏或数据科学应用中是经常需要的。
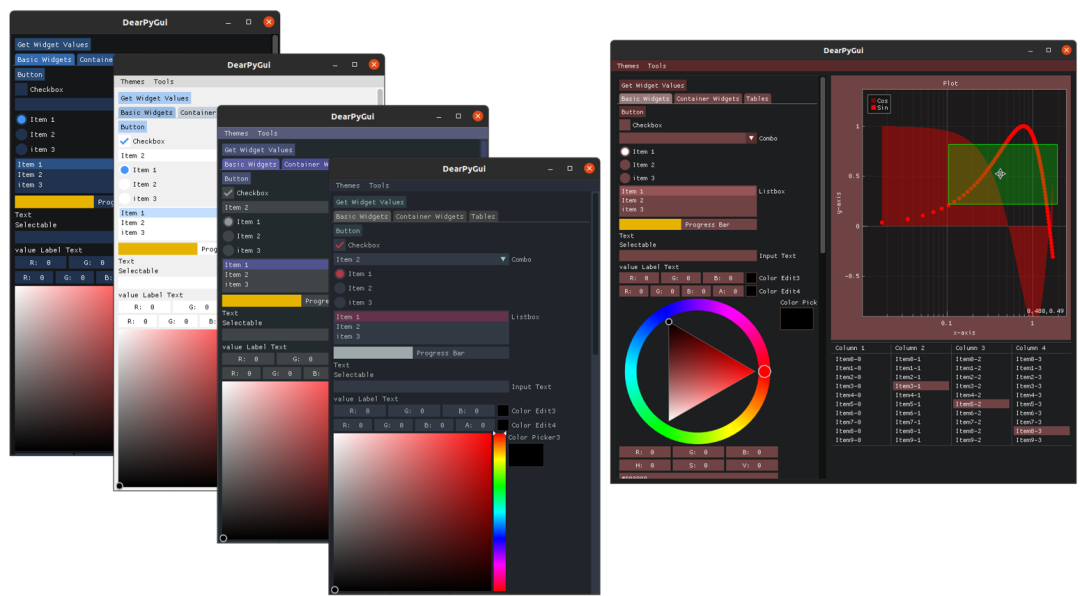
不需要非常陡峭的学习曲线,Dear PyGui 就能使用,并且可以在 Windows 10(DirectX 11)、Linux(OpenGL 3)和 MacOS(Metal)上运行。
GitHub 项目地址:https://github.com/hoffstadt/DearPyGui
4. PrettyErrors
简单的乐趣。这是让你思考的库之一:为什么以前没有人想到这个问题?
PrettyErrors 只做一件事,而且做到了极致。在支持彩色输出的终端中,它将隐秘的栈跟踪转换为更适合人类眼睛解析的东西。再也不用扫描整个屏幕来寻找异常的罪魁祸首了……现在,你就可以一眼发现它!
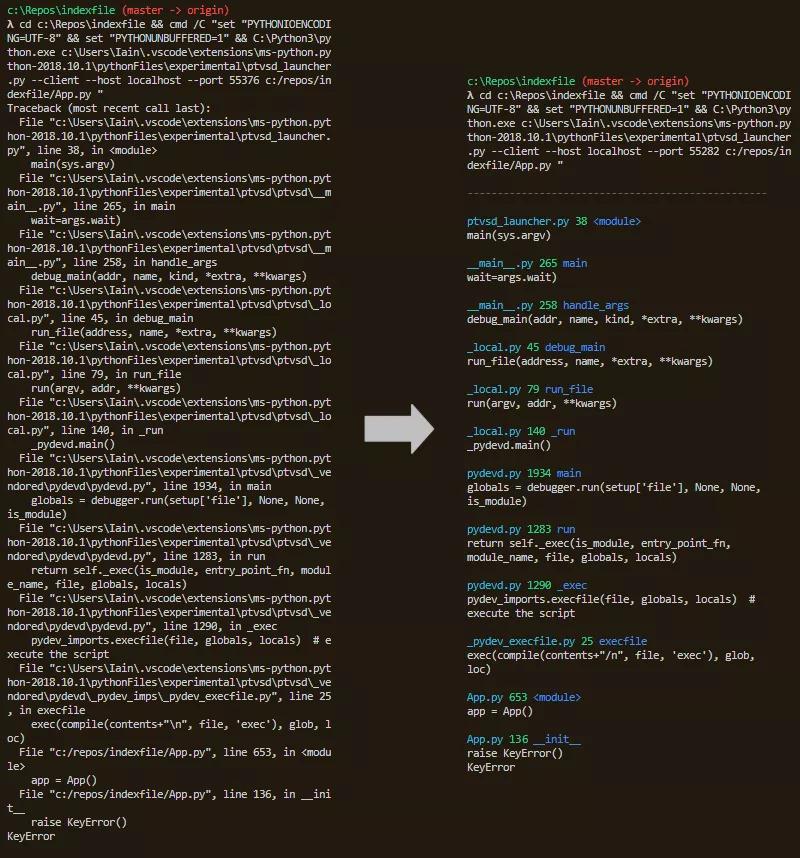
GitHub 项目地址:https://github.com/onelivesleft/PrettyErrors
5. Diagrams
我们程序员喜欢解决问题和编码。但是有时候,我们需要把复杂的架构设计作为项目文档的一部分来向其他同事解释。传统上,我们会求助于 GUI 工具,通过这种方式,我们就可以在图表和可视化方面做一些努力,并将其用于演示和文档。但是,这种方式并非唯一。
通过直接在 Python 代码中绘制云系统架构, Diagrams 允许你不使用任何设计工具。AWS、 Azure、 GCP 等多个云供应商都可以轻松地使用它的一些图标。这使得创建箭头和组变得非常简单。真的,它只有几行代码!
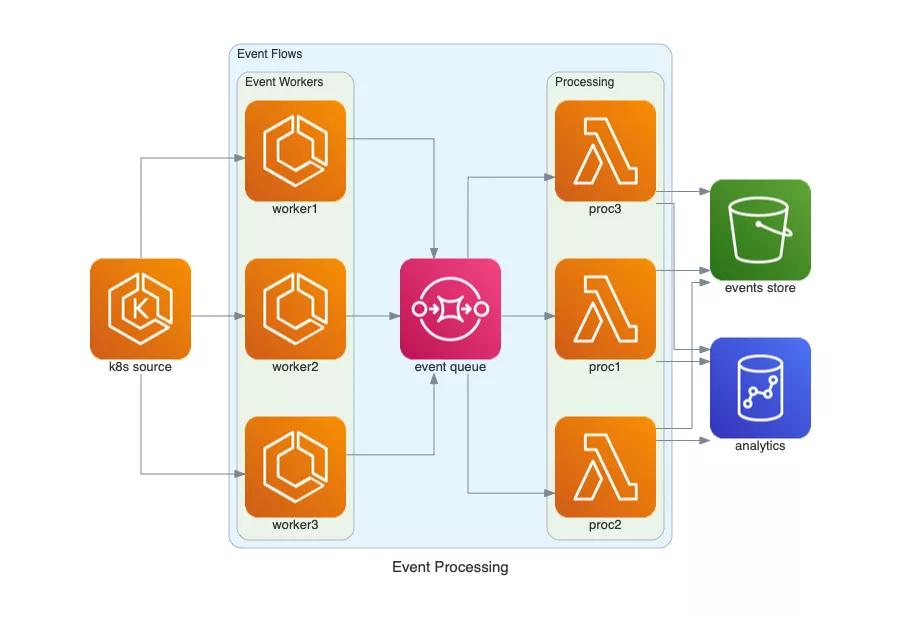
基于代码的 Diagrams 最好的地方是什么?通过标准 git,你可以跟踪版本控制的更改!开发人员将会非常高兴。
GitHub 项目地址:https://github.com/mingrammer/diagrams
6. Hydra 与 OmegaConf
当进行机器学习项目的研究和实验时,总是有无数的设置需要尝试。配置管理可以变得非常复杂,并且在重要的应用程序中非常快速。要是能找到处理这类复杂问题的结构方法该多好啊。
Hydra 是一种工具,它可以让你以一种可组合的方式构建配置,并从命令行或配置文件中覆盖某些部分。
为了说明使用该库所能简化的一些常见任务,假设我们正在实验的模型有一个基础架构,并且有多种变体。通过 Hydra,就可以定义一个基础配置,然后使用它们的变体运行多个作业。
python train_model.py variation=option_a,option_b
Hydra 的表亲 OmegaConf 为分层配置系统的基础提供了一致的 API,支持 YAML、配置文件、对象和 CLI 参数等不同的源。
它们是 21 世纪进行配置管理的必备之选。
7. PyTorch Lightning
任何能够提高数据科学团队生产力的工具都是价值连城。从事数据科学项目的人没有理由每次都要“重新发明轮子”,反复思考怎样才能更好地组织项目中的代码,怎样才能使用维护得不好的“PyTorch 样本代码”,怎样才能用潜在的控制来换取更高层次的抽象。
Lightning 通过将科学与工程脱钩来帮助提高生产力。这有点像 TensorFlow 的 Keras,从某种程度上说,这可以让代码更简洁。但这并不会剥夺你的控制权。PyTorch 仍然是 PyTorch,可以使用常用 API。
这个库可以帮助团队利用软件工程的良好实践,组织组件并明确职责,构建高质量的代码,从而方便地扩展到多个 GPU、 TPU 和 CPU 进行训练。
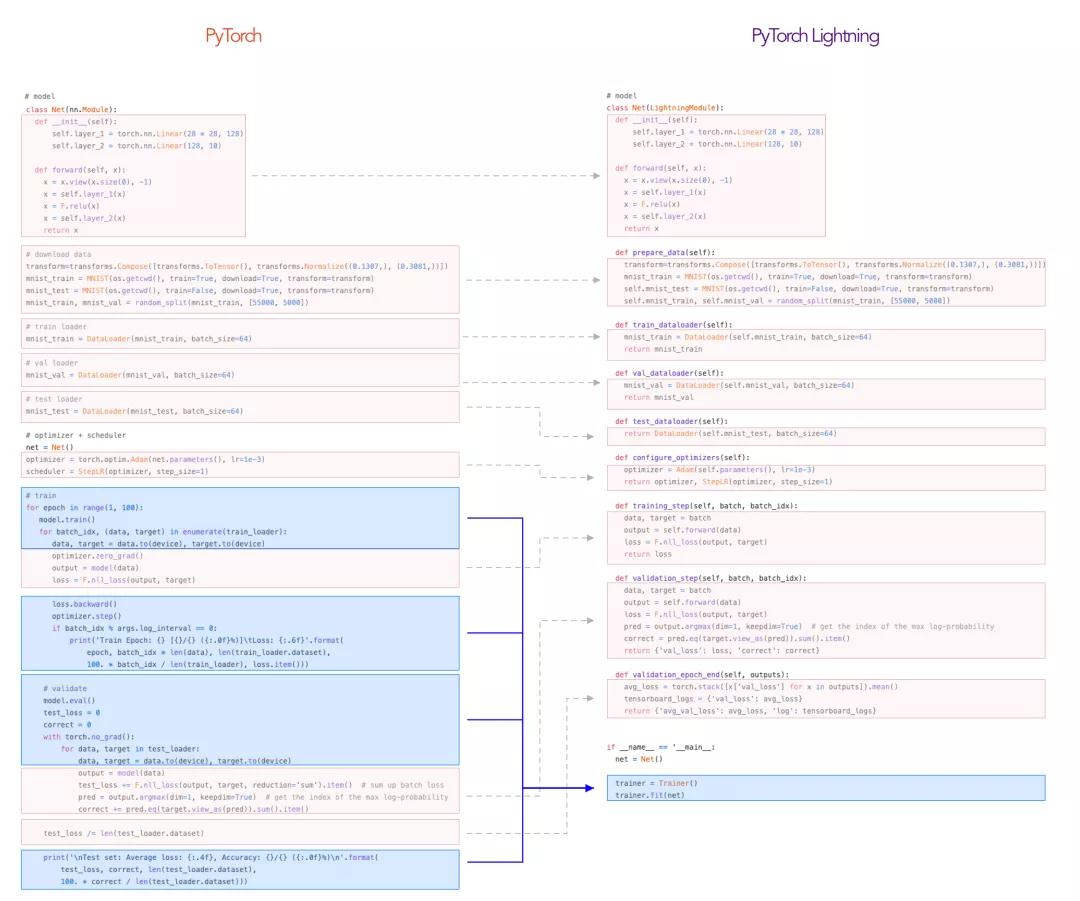
一个库,可以帮助数据科学团队中那些初级成员产生更好的结果,同时,更有经验的成员也会喜欢它,因为它可以在不放弃控制权的情况下,提高整体生产力。
GitHub 项目地址:
https://github.com/PyTorchLightning/PyTorch-lightning
8. Hummingbird

并非所有的机器学习都是深度学习。很多时候,你的模型由 scikit-learn 中实现的比较传统的算法组成(比如随机森林),或者你使用梯度提升方法,比如流行的 LightGBM 和 XGBoost。
但是,在深度学习领域,已经有了许多进展。诸如 PyTorch 这样的框架正在以惊人的速度发展,硬件设备也在优化,以更快的速度进行更低功耗的张量计算。如果我们能够利用这些努力,使我们的传统方法运行得更快更有效,岂不美哉?
这就是 Hummingbird 的用武之地。Microsoft 的这个新库可以将你训练好的传统机器学习模型编译成张量计算。这样做非常好,因为这样就无需重新设计模型。
截至目前,Hummingbird 支持向 PyTorch、TorchScript、ONNX 和 TVM,以及各种机器学习模型和矢量器的转换。推理 API 也非常类似于 Sklearn 范式,它可以让你重用现有的代码,但是将实现改为由 Hummingbird 生成。这是一个值得关注的工具,因为它获得了对模式模型和格式的支持!
GitHub 项目地址:
https://github.com/microsoft/hummingbird
9. HiPlot
几乎每一位数据科学家在其职业生涯中都会在某些时候处理高维数据。遗憾的是,人类的大脑并没有足够的能力来直观地处理这类数据,所以我们必须借助其他技术。
今年年初,Facebook 发布了 HiPlot,这是一个帮助发现高维数据中的相关性和模式的库,它使用平行图和其他图形方式来表示信息。这个概念在他们的发布博客文章中有过解释,但是这基本上是一个很好的方法来可视化和过滤高维数据。
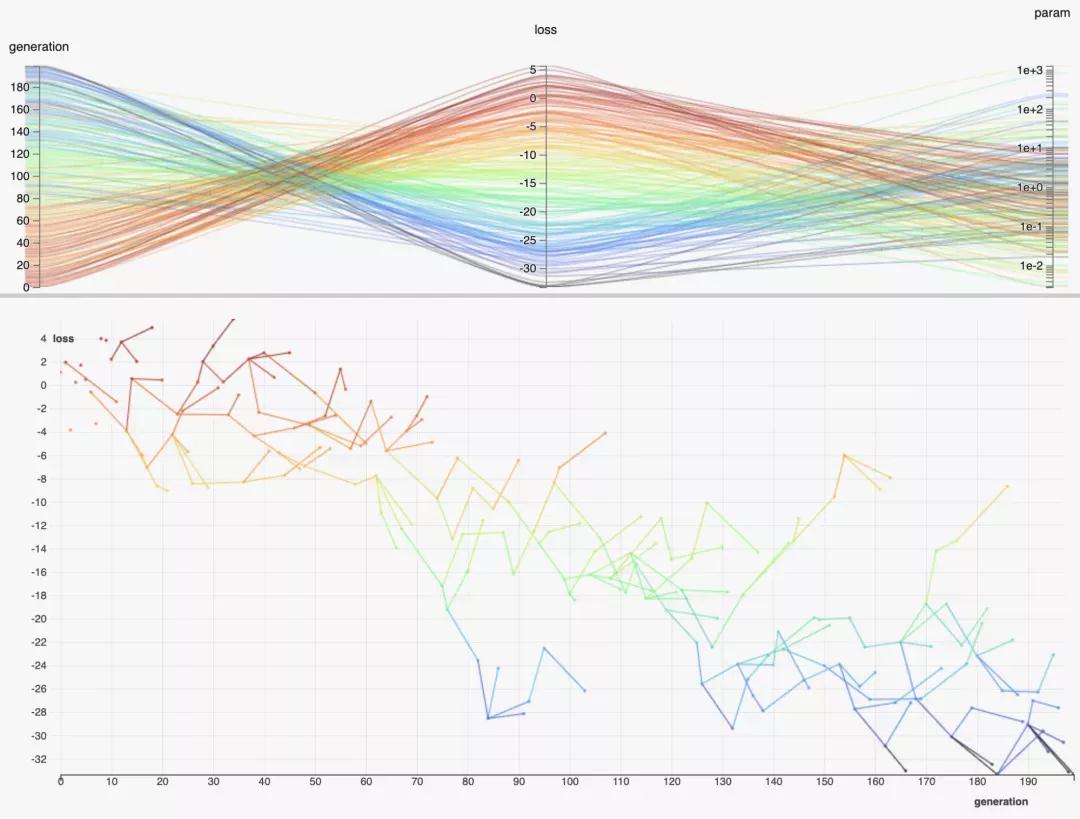
HiPlot 是交互式的、可扩展的,你可以在标准 Jupyter Notebooks 中使用 HiPlot,也可以通过自己的服务器来使用 HiPlot。
GitHub 项目地址:
https://github.com/facebookresearch/hiplot
10. Scalene
随着 Python 库的生态系统越来越复杂,我们发现自己编写的代码越来越依赖于 C 扩展和多线程代码。当涉及到测量性能时,这会成为一个问题,因为 CPython 中内置的分析器不能正确处理多线程代码和原生代码。
这时,Scalene 就来救场了。Scalene 是一个 CPU 和内存分析器,它针对 Python 脚本,能够正确地处理多线程代码,并区分运行 Python 与原生代码所花费的时间。无需修改代码,只需要用 Scalene 从命令行运行你的脚本,它就会为你生成一个文本或 HTML 报告,显示每行代码的 CPU 和内存使用情况。
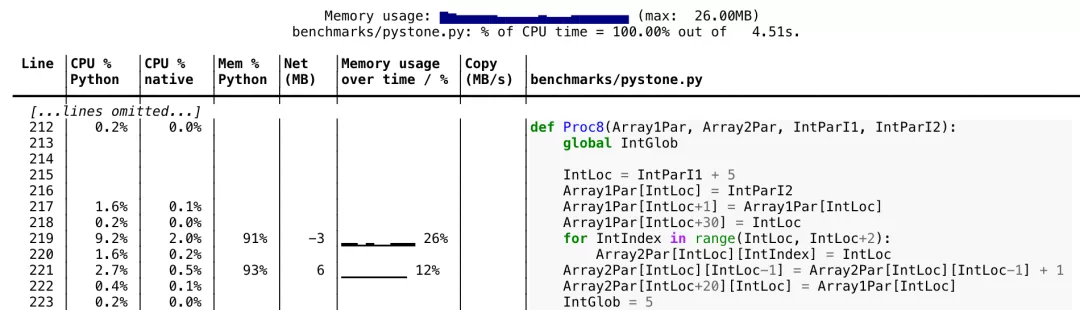
GitHub 项目地址:https://github.com/emeryberger/scalene
额外奖励:Norfair
Norfair 是一个可定制的轻量级 Python 库,用于实时对象跟踪。换句话来说,它为每一个被检测到的物体在不同的帧中分配了一个唯一的 id,允许你在它们随时间移动的过程中识别它们。有了 Norfair,只需要几行代码就可以为任何探测器添加跟踪功能。“任何探测器”?是的。无论对象的表现形式是什么样的:一个包围盒(4 个坐标),一个单点中心点,人体姿态估计系统的输出,或其他具有一定概率阈值以上变量的关键点的物体。
用于计算被跟踪物体与检测点之间距离的函数由用户定义,如果你需要,完全可以自定义。
它的速度也很快,而且可以实时操作。然而,真正的优势在于它是非常模块化的,你可以利用你现有的检测代码库,只需几行代码即可添加跟踪功能。
GitHub 项目地址:https://github.com/tryolabs/norfair
荣誉提名
quart:一个具有 Flask 兼容 API 的异步网络框架。一些现有的 Flask 扩展甚至可以工作。
alibi-detect:监控生产模型中的异常值和分布漂移,适用于表格数据、文本、图像和时间序列。
einops:einops 在 2020 年普及,可以让你为可读和可靠的代码编写张量操作,支持 NumPy、PyTorch、TensorFlow 等。Karpathy 推荐的,你还需要什么吗?
stanza:来自斯坦福的 60 多种语言的精确自然语言处理工具。多种可用的预训练模型用于不同的任务。
datasets:来自 HuggingFace 的轻量级可扩展库,可轻松共享和访问数据集,以及用于自然语言处理等评估指标。
pytorch-forecasting:在现实世界的案例和研究中,利用神经网络简化时间序列预测。
sktime:提供专门的时间序列算法和 scikit-learn 兼容工具,用于构建、调整和评估复合模型。也可以查看他们的配套 sktime-dl 包,用于基于深度学习的模型。
netron:一个用于神经网络、深度学习和机器学习模型的可视化工具。支持的格式比我所知道的还要多。
pycaret:封装了几个常见的机器学习库,使工作效率大大提高,并节省了数百行代码。
tensor-sensor:通过改进错误信息和提供可视化,帮助你获得张量数学的正确维度。
原文链接:https://tryolabs.com/blog/2020/12/21/top-10-python-libraries-of-2020/