

60道Python常见面试题,做对80% Offer任你挑!
资源专区;Python面试题汇总(150+道)

经典python面试题汇总,共计150+道。扫描文末二维码免费领取!
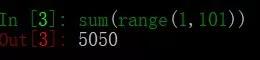
1、一行代码实现1--100之和
利用sum()函数求和
2、如何在一个函数内部修改全局变量
函数内部global声明 修改全局变量

3、列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
4、字典如何删除键和合并两个字典
del和update方法

5、谈下python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
6、python实现列表去重的方法
先通过集合去重,在转列表:

7、fun(*args,**kwargs)中的*args,**kwargs什么意思?

8、python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
9、一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
10、python内建数据类型有哪些
整型--int
布尔型--bool
字符串--str
列表--list
元组--tuple
字典--dict
11、简述面向对象中__new__和__init__区别
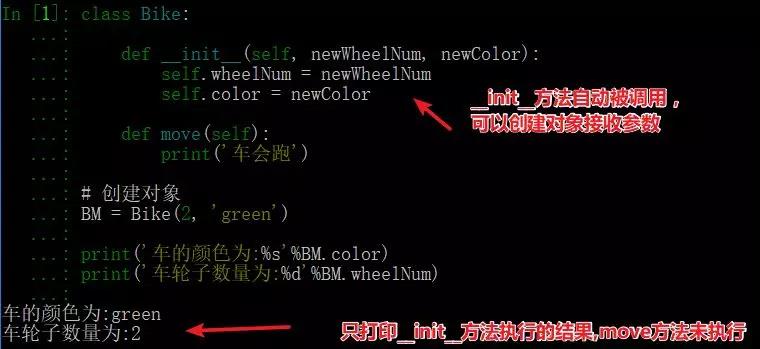
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数,如图
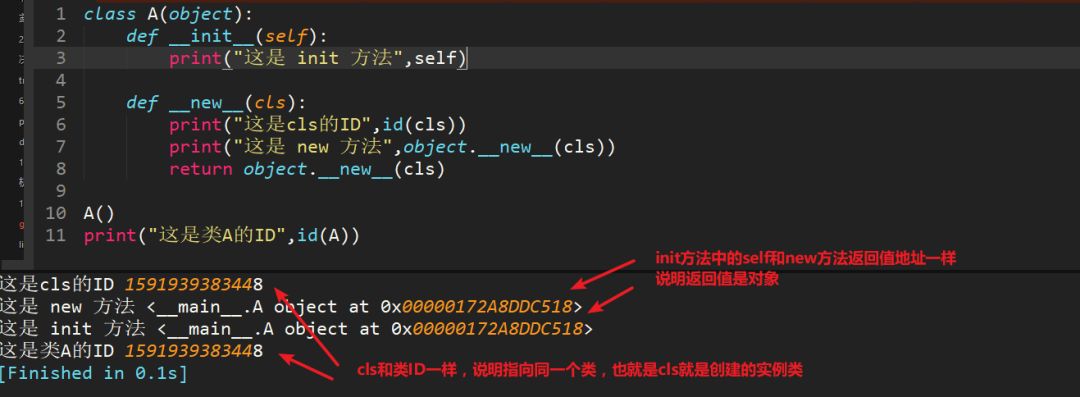
1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
12、简述with方法打开处理文件帮我我们做了什么?
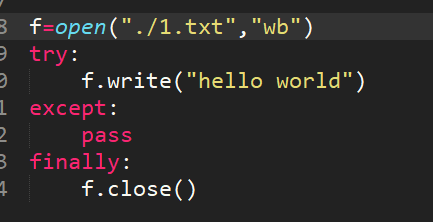
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open
写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
(当然还有其他自定义功能,有兴趣可以研究with方法源码)
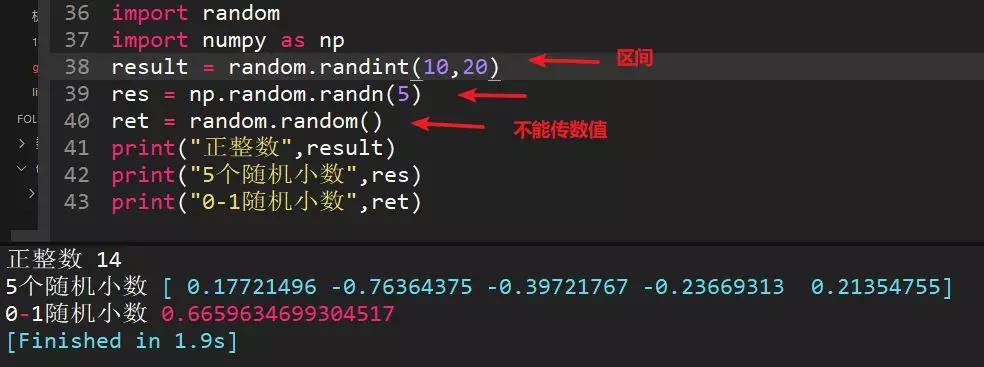
13、python中生成随机整数、随机小数、0--1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
0-1随机小数:random.random(),括号中不传参
14、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
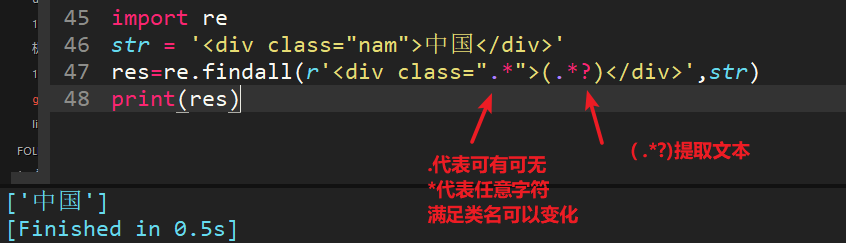
15、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的
16、python中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错

17、python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
18、列出python中可变数据类型和不可变数据类型,并简述原理
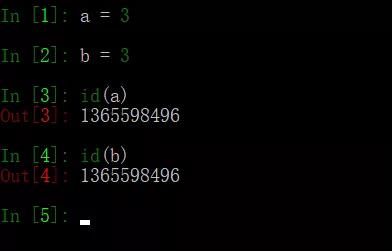
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id
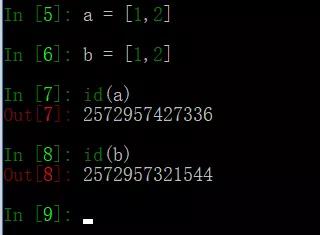
可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
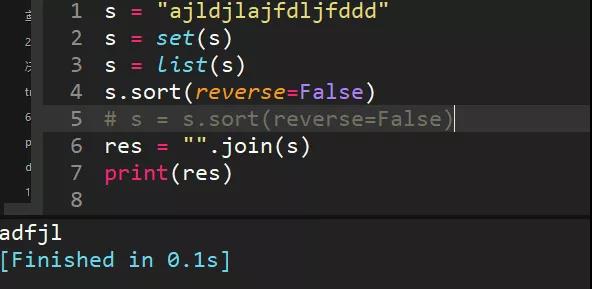
19、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"
set去重,去重转成list,利用sort方法排序,reeverse=False是从小到大排
list是不 变数据类型,s.sort时候没有返回值,所以注释的代码写法不正确
20、用lambda函数实现两个数相乘

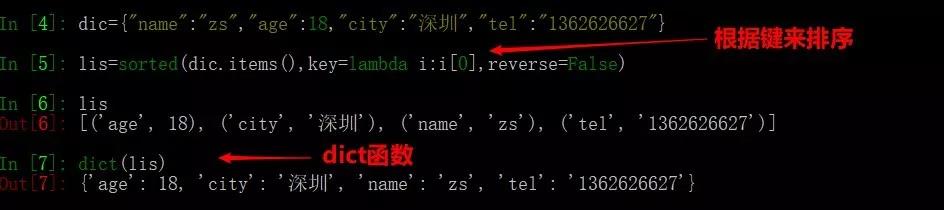
21、字典根据键从小到大排序
dic={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}
22、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
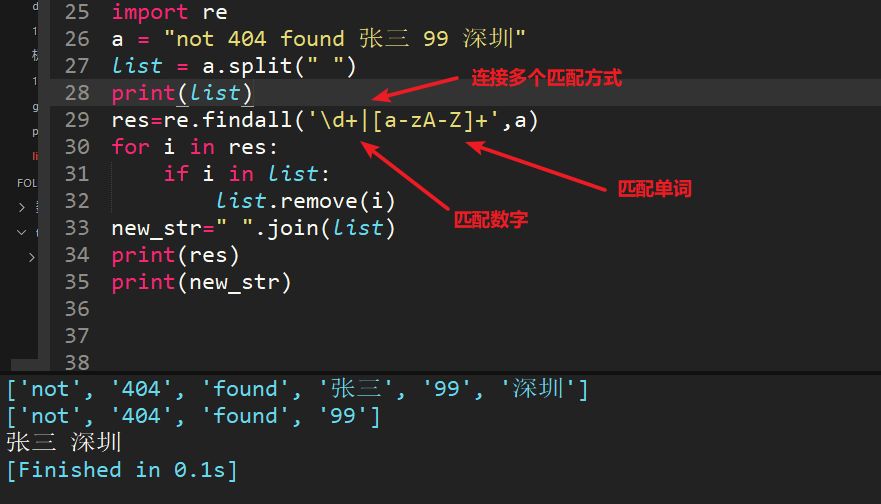
 23、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出 "张三 深圳"
23、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出 "张三 深圳"
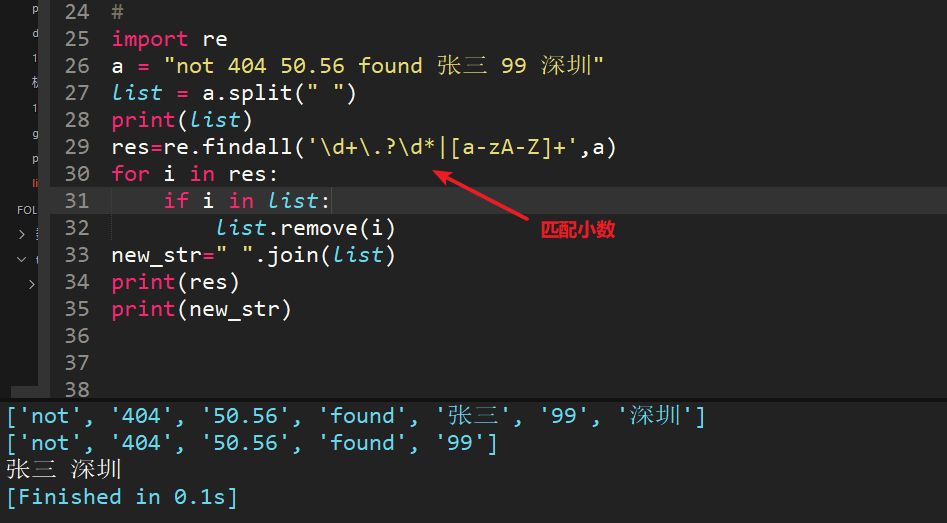
 顺便贴上匹配小数的代码,虽然能匹配,但是健壮性有待进一步确认
顺便贴上匹配小数的代码,虽然能匹配,但是健壮性有待进一步确认
24、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表
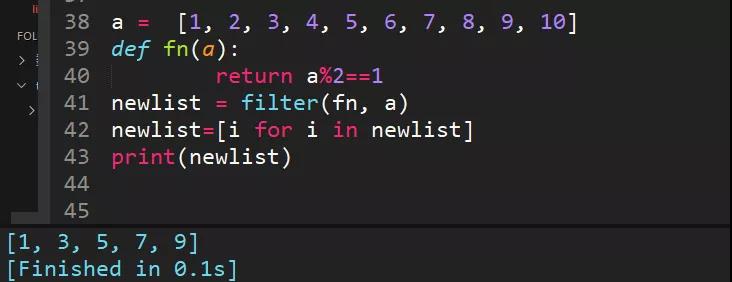
25、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
26、正则re.complie作用
re.compile是将正则表达式编译成一个对象,加快速度,并重复使用。
27、a=(1,)b=(1),c=("1") 分别是什么类型的数据?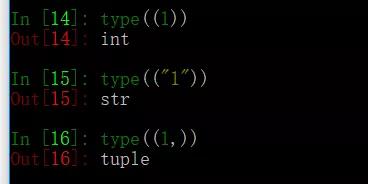
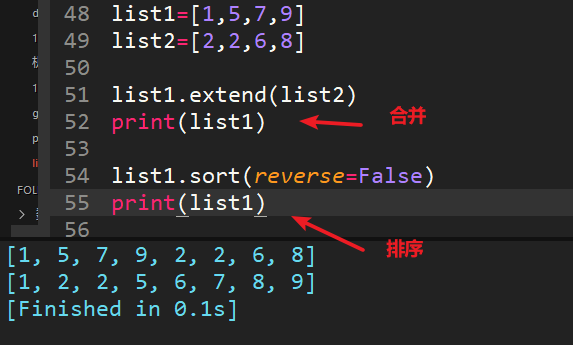
28、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]
extend可以将另一个集合中的元素逐一添加到列表中,区别于append整体添加。
29、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”
顺便把星期的代码也贴上了。

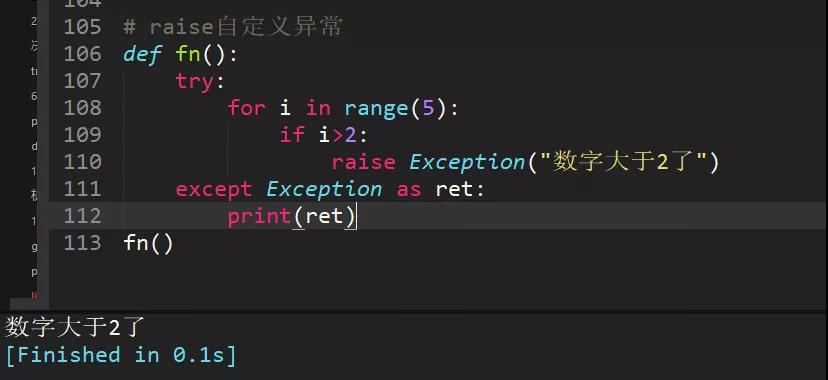
30、写一段自定义异常代码
自定义异常用raise抛出异常。
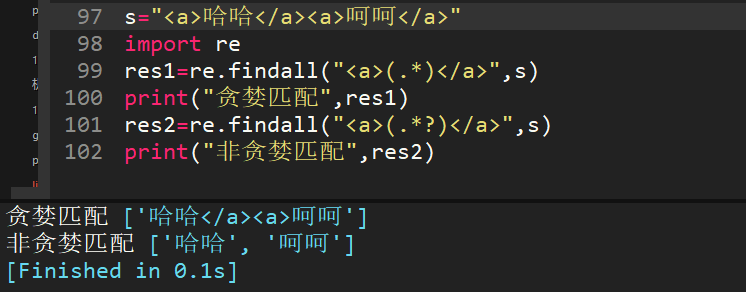
31、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配。
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配。
32、简述Django的orm
ORM,全拼Object-Relation Mapping,意为对象-关系映射。
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite....,如果数据库迁移,只需要更换Django的数据库引擎即可。
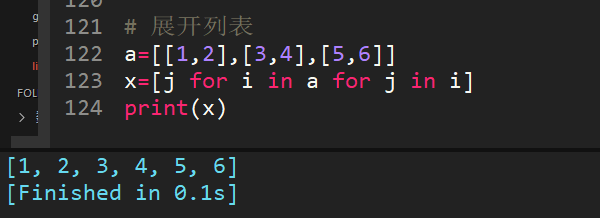
33、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]
列表推导式的骚操作。
运行过程:for i in a ,每个i是【1,2】,【3,4】,【5,6】,for j in i,每个j就是1,2,3,4,5,6,合并后就是结果。
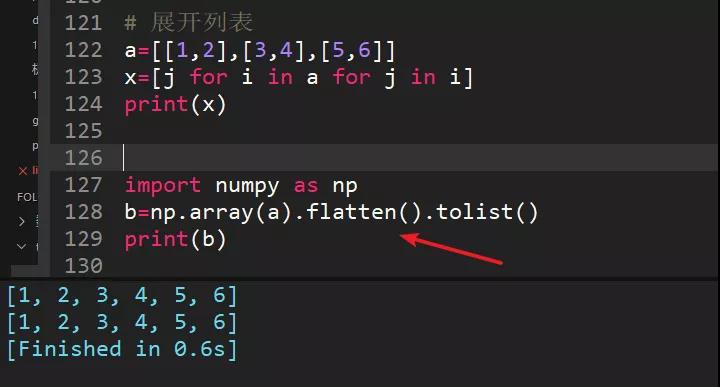
还有更骚的方法,将列表转成numpy矩阵,通过numpy的flatten()方法,代码永远是只有更骚,没有最骚。
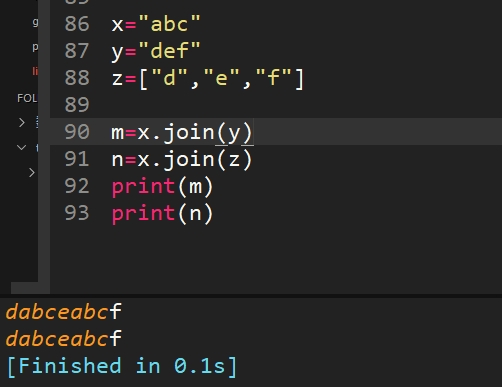
34、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果
join()括号里面的是可迭代对象,x插入可迭代对象中间,形成字符串,结果一致,有没有突然感觉字符串的常见操作都不会玩了。
顺便建议大家学下os.path.join()方法,拼接路径经常用到,也用到了join,和字符串操作中的join有什么区别,该问题大家可以查阅相关文档,后期会有答案。
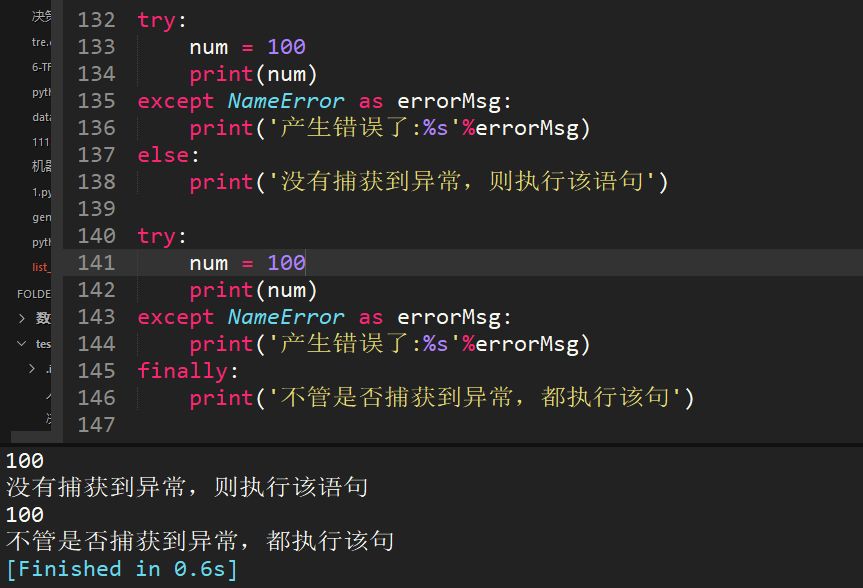
35、举例说明异常模块中try except else finally的相关意义
try..except..else没有捕获到异常,执行else语句。
try..except..finally不管是否捕获到异常,都执行finally语句。
36、举例说明zip()函数用法
zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
37、a="张明 98分",用re.sub,将98替换为100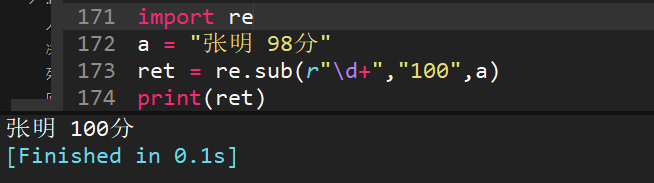
38、a="hello"和b="你好"编码成bytes类型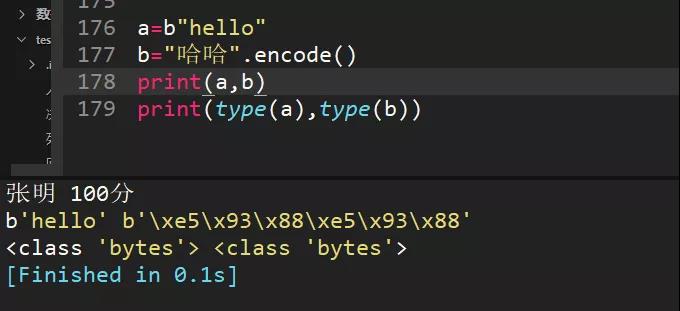
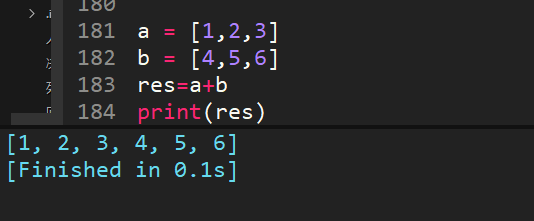
39、[1,2,3]+[4,5,6]的结果是多少?
两个列表相加,等价于extend。
40、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存;
2、循环代码优化,避免过多重复代码的执行;
3、核心模块用Cython PyPy等,提高效率;
4、多进程、多线程、协程;
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率。
41、遇到bug如何处理
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题。
42、正则匹配,匹配日期2018-03-20
url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
仍有同学问正则,其实匹配并不难,提取一段特征语句,用(.*?)匹配即可。

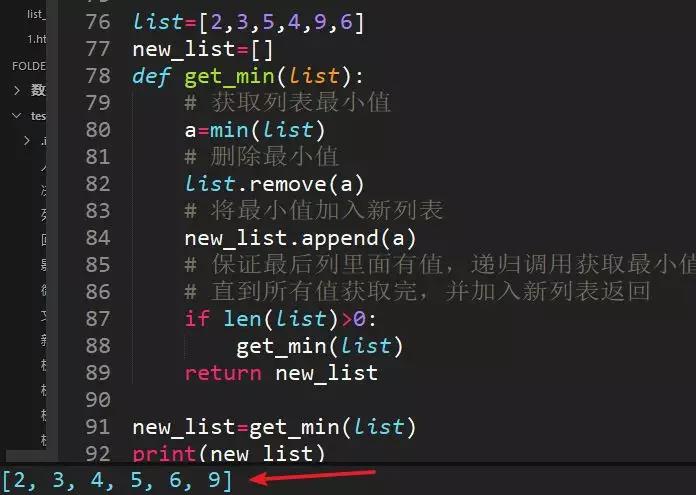
43、list=[2,3,5,4,9,6],从小到大排序,不许用sort,输出[2,3,4,5,6,9]
利用min()方法求出最小值,原列表删除最小值,新列表加入最小值,递归调用获取最小值的函数,反复操作。
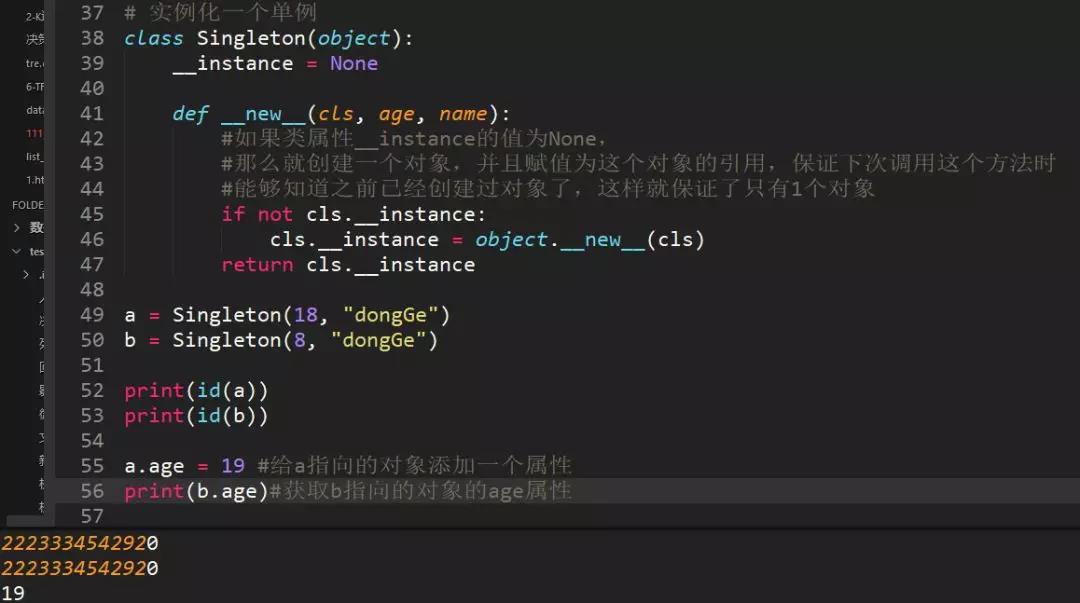
44、写一个单列模式
因为创建对象时__new__方法执行,并且必须return 返回实例化出来的对象所cls.__instance是否存在,不存在的话就创建对象,存在的话就返回该对象,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个。
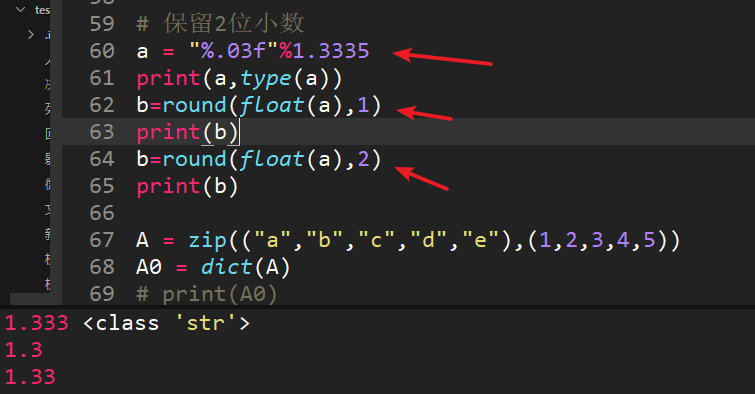
45、保留两位小数
题目本身只有a="%.03f"%1.3335,让计算a的结果,为了扩充保留小数的思路,提供round方法(数值,保留位数)。
46、求三个方法打印结果
fn("one",1)直接将键值对传给字典。
fn("two",2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对。
fn("three",3,{})因为传了一个新字典,所以不再是原先默认参数的字典。
47、分别从前端、后端、数据库阐述web项目的性能优化
该题目网上有很多方法,我不想截图网上的长串文字,看的头疼,按我自己的理解说几点。
前端优化:
1、减少http请求、例如制作精灵图;
2、html和CSS放在页面上部,javascript放在页面下面,因为js加载比HTML和Css加载慢,所以要优先加载html和css,以防页面显示不全,性能差,也影响用户体验差。
后端优化:
1、缓存存储读写次数高,变化少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存;
2、异步方式,如果有耗时操作,可以采用异步,比如celery;
3、代码优化,避免循环和判断次数太多,如果多个if else判断,优先判断最有可能先发生的情况。
数据库优化:
1、如有条件,数据可以存放于redis,读取速度快;
2、建立索引、外键等。
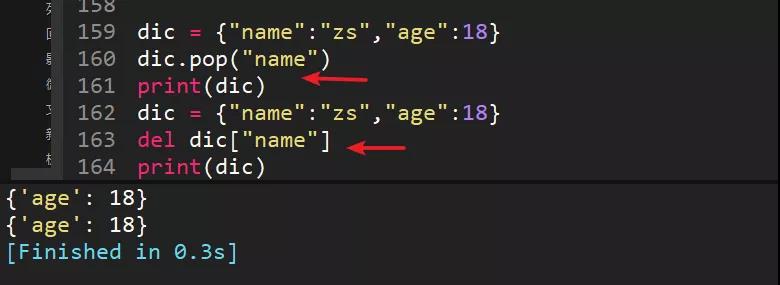
48、使用pop和del删除字典中的"name"字段,dic={"name":"zs","age":18}
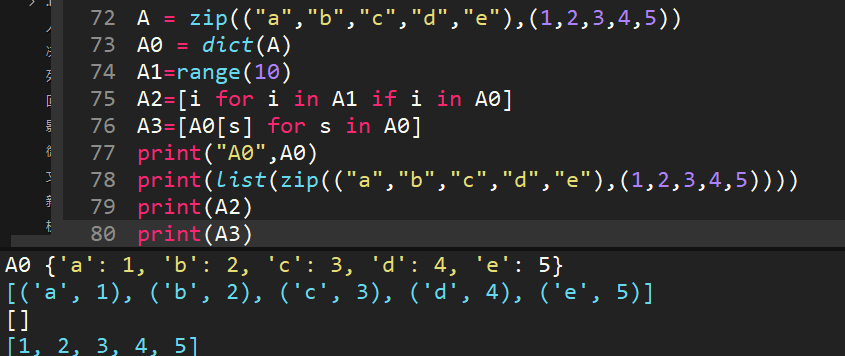
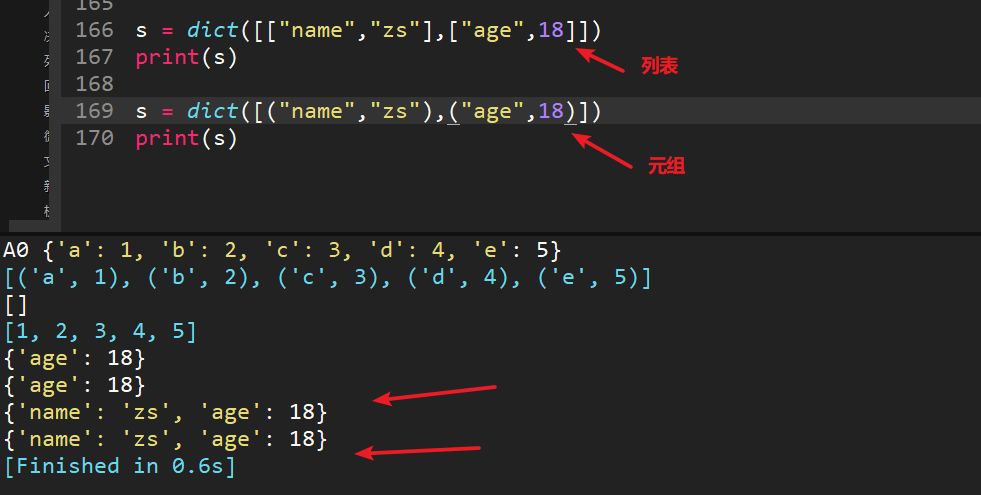
dict()创建字典新方法。
50、简述同源策略
同源策略需要同时满足以下三点要求:
1)协议相同
2)域名相同
3)端口相同
http:www.test.com与https:www.test.com 不同源——协议不同
http:www.test.com与http:www.admin.com 不同源——域名不同
http:www.test.com与http:www.test.com:8081 不同源——端口不同
只要不满足其中任意一个要求,就不符合同源策略,就会出现“跨域”。
51、简述cookie和session的区别
1,session 在服务器端,cookie 在客户端(浏览器);
2、session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效,存储Session时,键与Cookie中的sessionid相同,值是开发人员设置的键值对信息,进行了base64编码,过期时间由开发人员设置;
3、cookie安全性比session差。
52、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立;
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制。
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源;
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃。
应用:
1、IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间;
2、CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势。
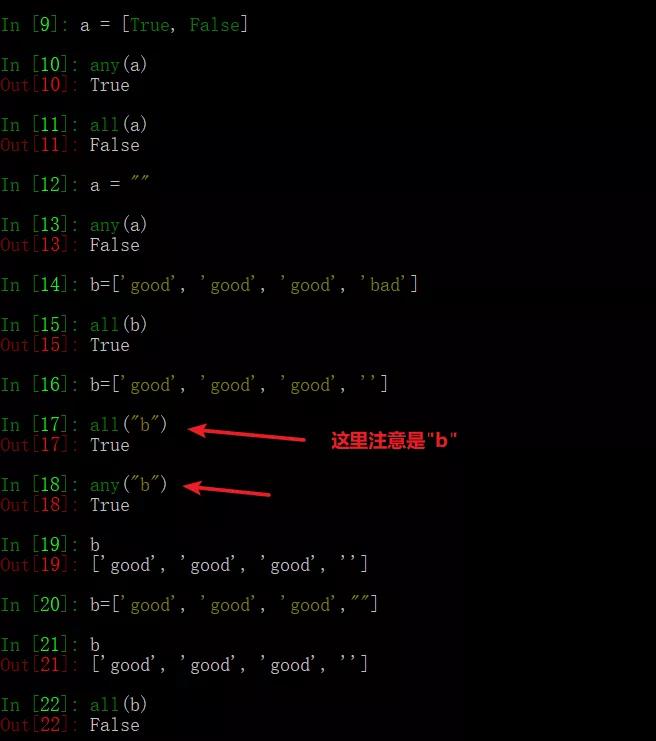
53、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真。
all():迭代器中所有的判断项返回都是真,结果才为真。
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
测试all()和any()方法。
54、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常。
AttributeError:试图访问一个对象没有的属性。
ImportError:无法引入模块或包,基本是路径问题。
IndentationError:语法错误,代码没有正确的对齐。
IndexError:下标索引超出序列边界。
KeyError:试图访问你字典里不存在的键。
SyntaxError:Python代码逻辑语法出错,不能执行。
NameError:使用一个还未赋予对象的变量。
55、python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
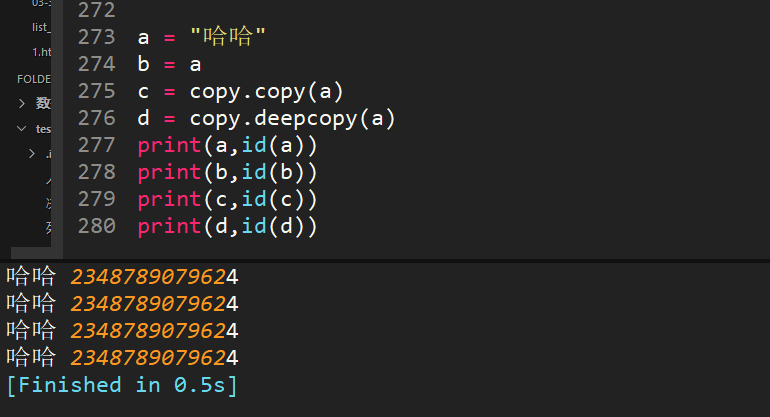
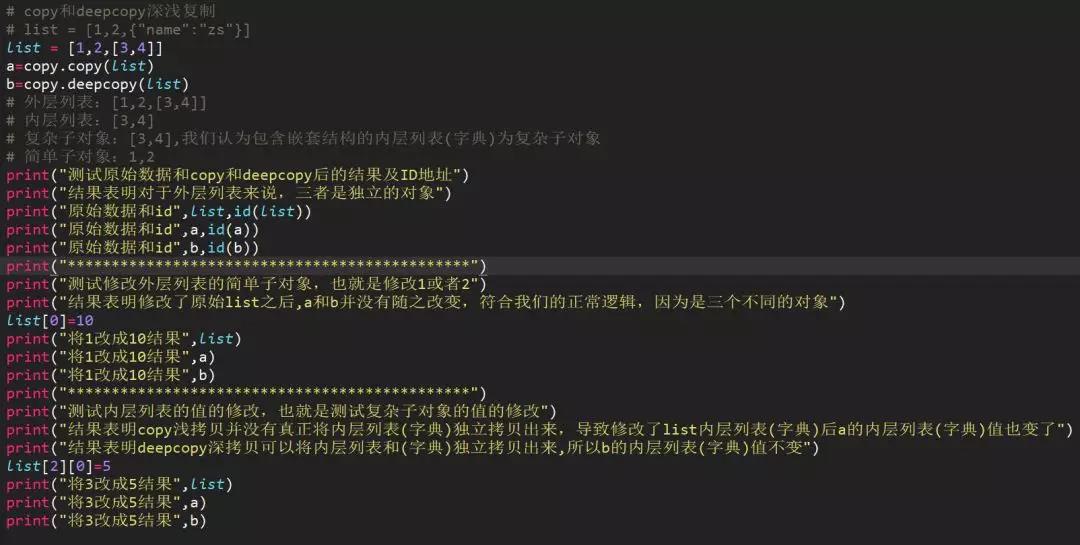
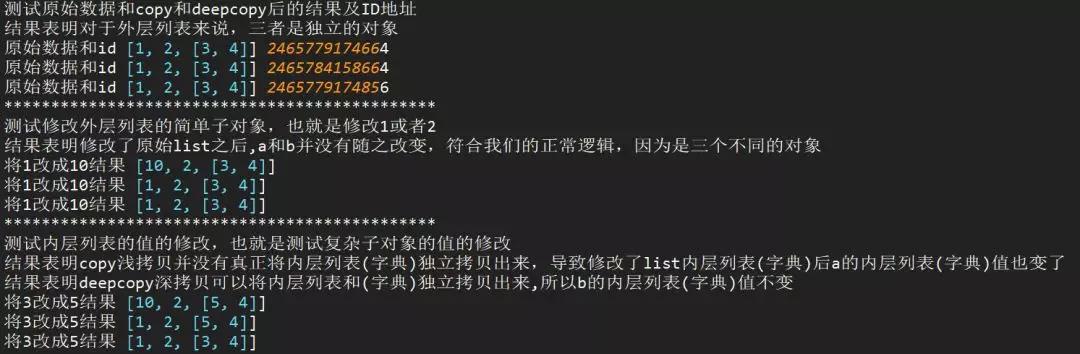
2、复制的值是可变对象(列表和字典)
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表), 改变原来的值 中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:完全复制独立,包括内层列表和字典。
56、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
57、C:\Users\ry-wu.junya\Desktop>python 1.py 22 33命令行启动程序并传参,print(sys.argv)会输出什么数据?
文件名和参数构成的列表。
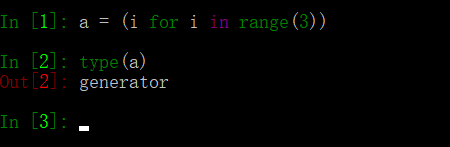
58、请将[i for i in range(3)]改成生成器
生成器是特殊的迭代器:
1、列表表达式的【】改为()即可变成生成器;
2、函数在返回值得时候出现yield就变成生成器,而不是函数了。
中括号换成小括号即可,有没有惊呆了
59、a = " hehheh ",去除收尾空格
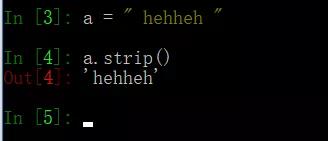
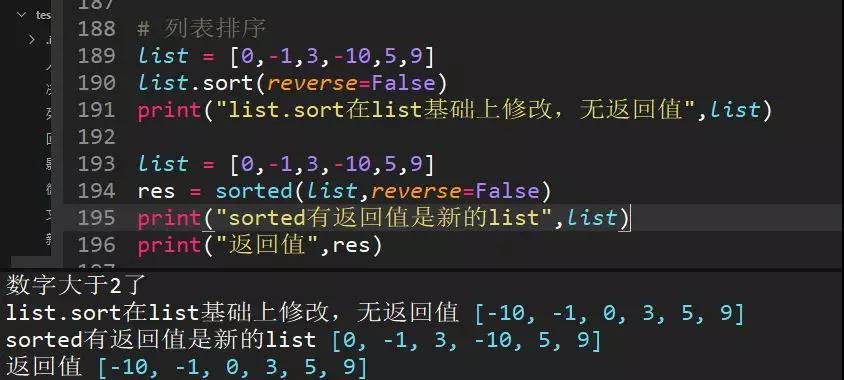
60、举例sort和sorted对列表排序,list=[0,-1,3,-10,5,9]
经典python面试题汇总,共计150+道。扫描下方二维码免费领取!

文章来源于网络,侵删!