首页
高薪实战项目班
new
Linux云计算SRE
Python全能开发
云原生微服务实战
go高并发实战
网络安全攻防渗透
DevOps项目实战
华为鸿蒙NEXT培训
AIGC大模型应用开发
AI大模型微调
AIGC大模型应用实战
Rust工程师进阶实战
考试认证
hot
阿里云认证
RHCE
CKA/CKS
CISP
Nginx
软考-高级系统分析师
软考-高级系统规划管理师
软考-高级系统架构与设计师
技术学习教程
Linux云计算实战
python学习教程
网络安全
go开发实战
云原生及微服务
大数据学习
数据库
免费试学
就业喜讯
马哥教育动态
马哥头条
企业名师
一线企业教练
开课动态
就业喜讯
行业合作
产品升级
校企合作
官方支付通道
马哥教育官网
首页
技术干货
Python开发
用Python执行SQL、Excel常见任务?10个方法全搞定!
Python开发
,
技术干货
,
马哥教育快报
2021年4月19日 上午11:10
4106
数据从业者有许多工具可用于分割数据。有些人使用 Excel,有些人使用SQL,有些人使用Python。对于某些任务,使用 Python 的优点是显而易见的。以更快的速度处理更大的数据集。使用基于 Python 构建的开源机器学习库。你可以轻松导入和导出不同格式的数据。
由于其多功能性,Python 可以成为任何数据分析师工具箱的重要组成部分。但是,这很难开始。大多数数据分析师可能熟悉 SQL 或 Excel。本篇是涉及帮助你将技能和技术从 EXcel 和 SQL 转移到 Python。
首先,让我们来设置 Python。最简单的方法就是使用 Jupyter Notebook 和 Anaconda。这个可视化界面将允许你插入 Python 代码并立即查看输出。这也将使你轻松跟随本教程的其余部分。
我强烈推荐使用 Anaconda,但这个初学者指南也将帮助你安装 Python——尽管这将使本篇文章更加难以接受。
我们从基础开始:打开一个数据集。
01 导入数据
你可以导入.sql 数据库并用 SQL 查询中处理它们。在Excel中,你可以双击一个文件,然后在电子表格模式下开始处理它。在 Python 中,有更多复杂的特性,得益于能够处理许多不同类型的文件格式和数据源的。
使用一个数据处理库 Pandas,你可以使用 read 方法导入各种文件格式。使用这个方法所能导入完整的文件格式清单是在 Pandas 文档中。你可以导入
从 CSV 和 Excel 文件到 HTML 文件中的所有内容!
使用 Python 的最大优点之一是能够从网络的巨大范围中获取数据的能力,而不是只能访问手动下载的文件。在 Python 的requests 库可以帮助你分类不同的网站,并从它们获取数据,而 BeautifulSoup 库可以帮助你处理和过滤数据,那么你将精确得到你所需要的。如果你要去这条路线,请小心使用权问题。
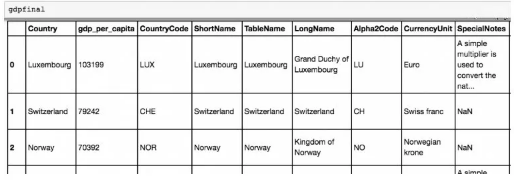
在这个例子中,我们将获取许多国家人均 GDP(一个技术术语,意思是一个国家的人均收入)的维基百科表格,
并在 Python 中使用 Pandas 库对数据进行排序。
首先,导入我们需要的库。
需要 Pandas 库处理我们的数据。需要 numpy 库来执行数值的操作和转换。我们需要 requests 库来从网站获取 HTML 数据。需要 BeautifulSoup 来处理这些数据。最后,需要 Python(re)的正则表达式库来更改在处理数据时将出现的某些字符串。
在 Python 中,不需要知道很多关于正则表达式的知识,但它们是一个强大的工具,
可用于匹配和替换某些字符串或子字符串。
如果你想了解更多,请参考以下内容。
02 信任这个网站的一些代码
这是一个更具技术性的解释,详细说明如何使用 Python 代码来获取 HTML 表格。
你可以将上面的代码复制粘贴到你自己的 Anaconda 中,如果你用一些 Python 代码运行,可以迭代它!
下面是代码的输出,如果你不修改它,就是所谓的字典。
你会注意到逗号分隔起来的括号的 key-value 列表。每个括号内的列表都代表了我们 dataframe 中的一行,每列都以 key 表示:我们正在处理一个国家的排名,人均 GDP(以美元表示)及其名称(用「国家」)。
有关数据结构,如列表和词典,如何在 Python 中的运行的更多信息,本篇将有所帮助。
幸运的是,为了将数据移动到 Pandas dataframe 中,我们不需要理解这些数据,
这是将数据聚合到 SQL 表或 Excel 电子表格的类似方式。
使用一行代码,我们已经将这些数据分配并保存到 Pandas dataframe 中 —— 事实证明是这种情况,字典是要转换为 dataframe 的完美数据格式。
通过这个简单的 Python 赋值给变量 gdp,我们现在有了一个 dataframe,可以在我们编写 gdp 的时候打开和浏览。我们可以为该词添加 Python 方法,
以创建其中的数据的策略视图。
作为我们刚刚在 Python 中使用等号和赋值的一点深入了解,很有帮助。
03 快速查看数据
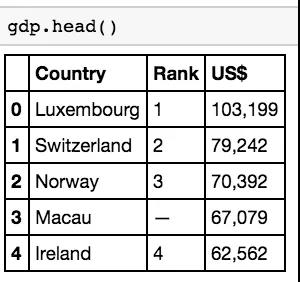
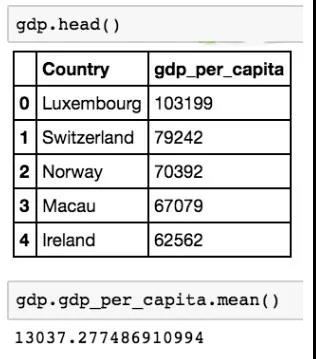
现在,如果要快速查看我们所做的工作,我们可以使用 head() 方法,它与 Excel 中的选择几行或SQL中的 LIMIT 方法非常相似。轻松地使用它来快速查看数据集,而无需加载整个数据集!如果要查看特定数量的行,还可以在 head() 方法中插入行数。
我们得到的输出是人均 GDP 数据集的前五行(head 方法的默认值),我们可以看到它们整齐地排列成三列以及索引列。请注意,
Python 索引从0开始,而不是1,
这样,如果要调用 dataframe 中的第一个值,则使用0而不是1!你可以通过在圆括号内添加你选择的数字来更改显示的行数。试试看!
04 重命名列
有一件你在 Python 中很快意识到的事是,具有某些特殊字符(例如$)的名称处理可能变得非常麻烦。我们将要
重命名某些列
,在 Excel 中,可以通过单击列名称并键入新名称,在SQL中,你可以执行 ALTER TABLE 语句或使用 SQL Server 中的 sp_rename。
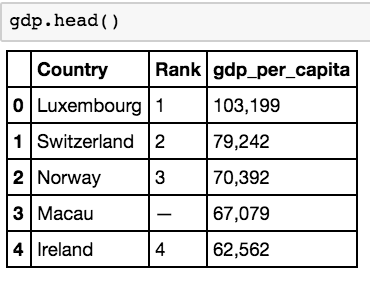
在 Pandas 中,这样做的方式是rename 方法。
在实现上述方法时,我们将使用列标题
「gdp_per_capita」 替换列标题「US $」
。一个快速的 .head() 方法调用确认已经更改。
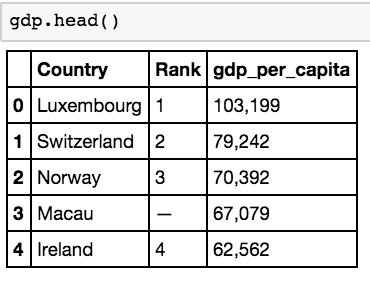
05 删除列
有一些数据损坏!如果你查看 Rank 列,你会注意到散乱的随机破折号。这不是很好,由于实际的数字顺序被破坏,这使得 Rank 列无用,特别是使用 Pandas 默认提供的编号索引。
幸运的是,使用内置的 Python 方法:
del
,删除列变得很容易。
现在,通过另外调用 head 方法,我们可以确认 dataframe 不再包含 rank 列。
06 在列中转换数据类型
有时,给定的数据类型很难使用。这个方便的教程将分解 Python 中不同数据类型之间的差异,以便你需要复习。
在 Excel 中,你可以右键单击并找到将列数据转换为不同类型的数据的方法。你可以复制一组由公式呈现的单元格,并将其粘贴为值,你可以使用格式选项快速切换数字,日期和字符串。
有时候,在 Python 中切换一种数据类型为其他数据类型并不容易,但当然有可能。
我们首先在 Python 中使用 re 库。我们将使用
正则表达式来替换 gdp_per_capita 列中的逗号
,以便我们可以更容易地使用该列。
re.sub 方法本质上是使用空格替换逗号。以下详细介绍了 re库 的各个方法。
现在我们已经删除了逗号,我们可以轻易地将列转换为数字。
现在我们可以计算这列的平均值。
我们可以看到,人均 GDP 的平均值约为13037.27美元,如果这列被判断为字符串(不能执行算术运算),我们就无法做到这一点。现在,可以对我们以前不能做的人均 GDP 列进行各种计算,包括通过不同的值过滤列,并确定列的百分位数值。
07 选择/过滤数据
任何数据分析师的基本需求是
将大型数据集分割成有价值的结果。
为了做到这一点,你必须检查一部分数据:这对选择和过滤数据是非常有帮助的。在 SQL 中,这是通过混合使用 SELECT 和不同的其他函数实现的,而在 Excel 中,可以通过拖放数据和执行过滤器来实现。
你可以使用 Pandas 库不同的方法或查询快速过滤。
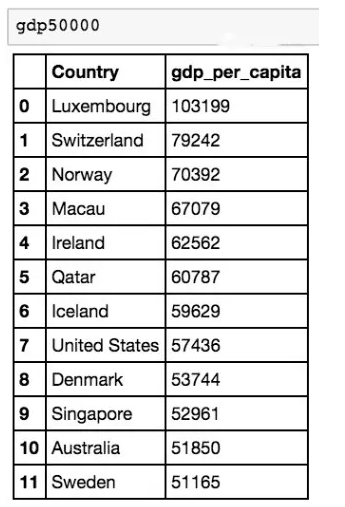
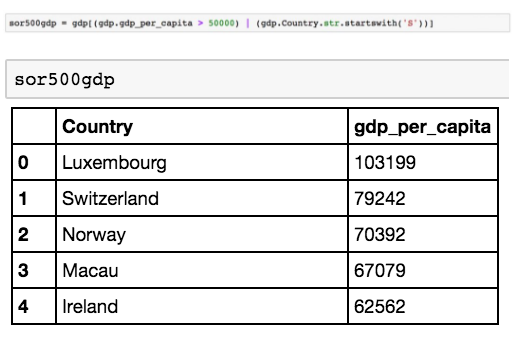
作为一个快速的代表,只显示人均 GDP 高于 5 万美元的国家。
这是这样做到的:
我们为一个新的 dataframe 分配一个布尔索引的过滤器,这个方法基本上就是说「创建一个人均 GDP 超过 50000 的新 dataframe」。现在我们可以显示gdp50000。
有12个国家的 GDP 超过 50000!
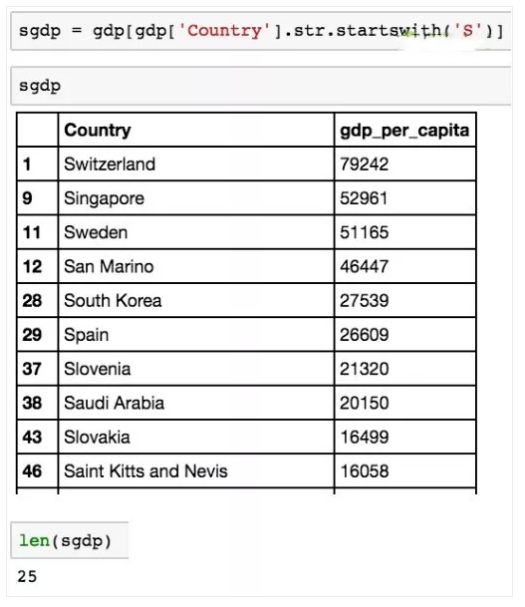
选择属于以 s 开头的国家的行。
现在可以显示一个新 dataframe,其中只包含以 s 开头的国家。使用 len 方法快速检查(一个用于计算 dataframe 中的行数的救星!)表示我们有 25 个国家符合。
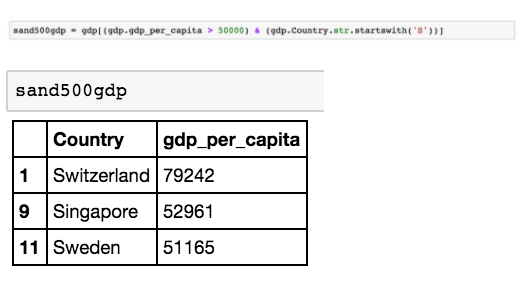
要是我们想把这两个过滤条件连在一起呢?
这里是连接过滤的方法。在多个过滤条件之前,你想要了解它的工作原理。你还需要了解 Python 中的基本操作符。为了这个练习的目的,你只需要知道
「&」代表 AND,而「|」代表 Python 中的 OR。
然而,通过更深入地了解所有基础运算符,你可以用各种条件轻松地处理的数据。
让我们继续工作,并在过滤选择以「S」开头且有大于 50,000 人均 GDP 的国家。
现在过滤以「S」开头 或人均 GDP 超过 50000 的国家。
我们正在努力处理 Pandas 中的过滤视图。
08 用计算机来处理数据
没有可以帮助计算不同的结果的方法,那么 Excel 会变成什么?
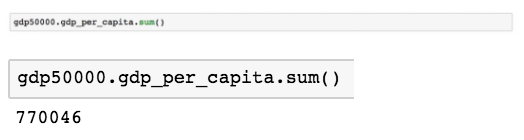
在这种情况下,Pandas 大量依赖于 numpy 库和通用 Python 语法将计算放在一起。对我们一直在研究的 GDP 数据集进行一系列简单的计算。例如,计算人均国民生产总值超过 5 万的总和。
这将给你答案为 770046 。使用相同的逻辑,我们可以计算各种的值 — 完整列表位于左侧菜单栏下的计算/描述性统计部分的 Pandas 文档。
09 数据可视化(图表/图形)
数据可视化是一个非常强大的工具 – 它允许你以可理解的格式与其他人分享你获得的见解。毕竟,一张照片值得一千字。SQL 和 Excel 都具有将查询转换为图表和图形的功能。使用 seaborn 和 matplotlib 库,你可以使用 Python 执行相同操作。
有关数据可视化选项的综合的教程 – 我最喜欢的是这个 Github readme document (全部在文本中),它解释了如何在 Seaborn 中构建概率分布和各种各样的图。这应该让你了解 Python 中数据可视化的强大功能。如果你感到不知所措,你可以使用一些解决方案,如Plot.ly,这可能更直观地掌握。
我们不会检查每一个数据可视化选项,只要说使用 Python,可以比任何 SQL 提供的功能具有更强大的可视化功能,必须权衡
使用 Python 获得更多的灵活性,
以及在 Excel 中通过模板生成图表的简易性。
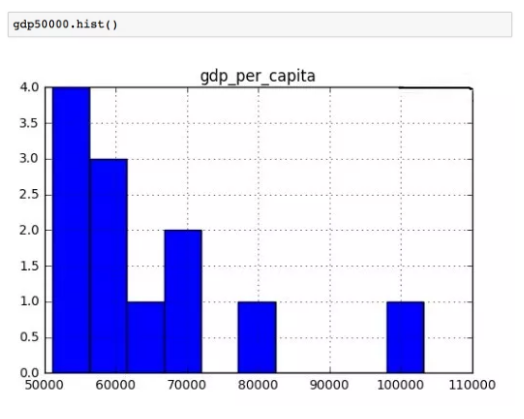
在这种情况下,我们将建立一个简单的直方图,显示人均 GDP 超过 5 万美元的国家的人均 GDP 分布。
有了这个强大的直方图方法 (hist()),我们现在可以生成一个直方图,显示出大部分人均 GDP 在 5 万到 7 万美元之间!
10 分组和连接数据
在 Excel 和 SQL 中,诸如 JOIN 方法和数据透视表之类的强大工具可以快速汇总数据。
Pandas 和 Python 共享了许多从 SQL 和 Excel 被移植的相同方法。可以
在数据集中对数据进行分组,并将不同的数据集连接在一起。
你可以看看这里的文档。你会发现,由 Pandas 中的merge 方法提供的连接功能与 SQL 通过 join 命令提供的连接功能非常相似,而 Pandas 还为过去在 Excel 中使用数据透视表的人提供了 pivot table 方法。
我们将制定的人均 GDP 的表格与世界银行的世界发展指数清单进行简单的连接。
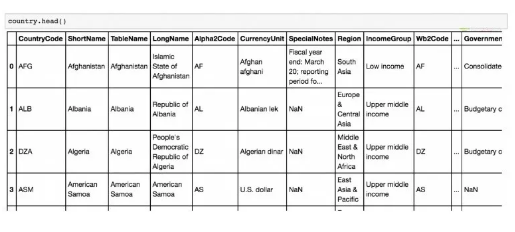
首先导入世界发展指数的 .csv文件。
使用 .head() 方法快速查看这个数据集中的不同列。
现在我们完成了,我们可以快速看看,添加了几个可以操作的列,包括不同年份的数据来源。
现在我们来合并数据:
我们现在可以看到,这个表格包含了人均 GDP 列和具有不同列的遍及全国的数据。对于熟悉 SQL join 的用户,你可以看到我们正在对原始 dataframe 的 Country 列进行内部连接。
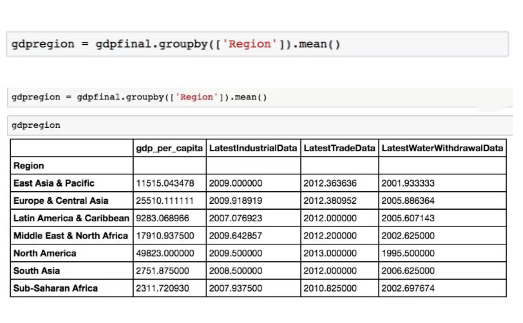
现在我们有一个连接表,我们希望将国家和人均 GDP 按其所在地区进行分组。
我们现在可以使用 Pandas 中的 group 方法排列按区域分组的数据。
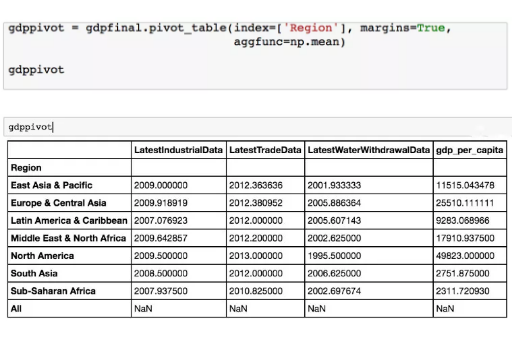
要是我们想看到 groupby 总结的永久观点怎么办?Groupby 操作创建一个可以被操纵的临时对象,但是它们不会创建一个永久接口来为构建聚合结果。为此,我们必须使用 Excel 用户的旧喜爱:数据透视表。幸运的是,Pandas 拥有强大的数据透视表方法。
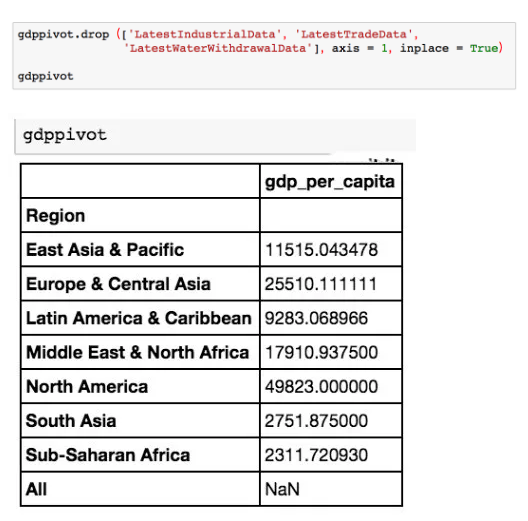
你会看到我们收集了一些不需要的列。幸运的是,使用 Pandas 中的 drop 方法,你可以轻松地删除几列。
现在我们可以看到,人均 GDP 根据世界不同地区而不同。我们有一个干净的、包含我们想要的数据的表。
这是一个非常肤浅的分析:你想实际做一个加权平均数,因为每个国家的人均 GDP 不代表一个群体中每个国家的人均 GDP,因为在群体中的人口不同。
事实上,你将要重复我们所有的计算,包括反映每个国家的人口列的方法!看看你是否可以在刚刚启动的 Python notebook 中执行此操作。如果你可以弄清楚,你将会很好地将 SQL 或 Excel 知识转移到 Python 中。
文章转载:菜鸟学Python
(版权归原作者所有,侵删)
相关新闻
【Linux面试真题】- Linux软连接和硬链接的区别:
新一代子域名收集工具!
Python必备-python文件打包实战技巧
Python爬虫实战之使用Scrapy爬起点网的完本小说
新手Linux运维要知道的Linux常用命令
【Git第十节】版本回退
Python 库 PyPI 遭受危机!
小白如何操作Python字符串(五)
【学员喜讯-739期】马哥教育面授班-应届毕业生,还没拿到毕业证,已成功取得offer,年薪13万!
Linux系统安全之syslog命令解析【每日一个知识点第86期-Linux】
分享到:
微博
微信
微信扫码分享
QQ好友
QQ空间
豆瓣
LinkedIn
Facebook
X
历经多年发展,已成为国内好评如潮的Linux云计算运维、SRE、Devops、网络安全、云原生、Go、Python开发专业人才培训机构!
1/
close the image dialog
go to the previous image
go to the next image